# 数据开发
本章节包含以下步骤:
# 1. 创建项目及配置
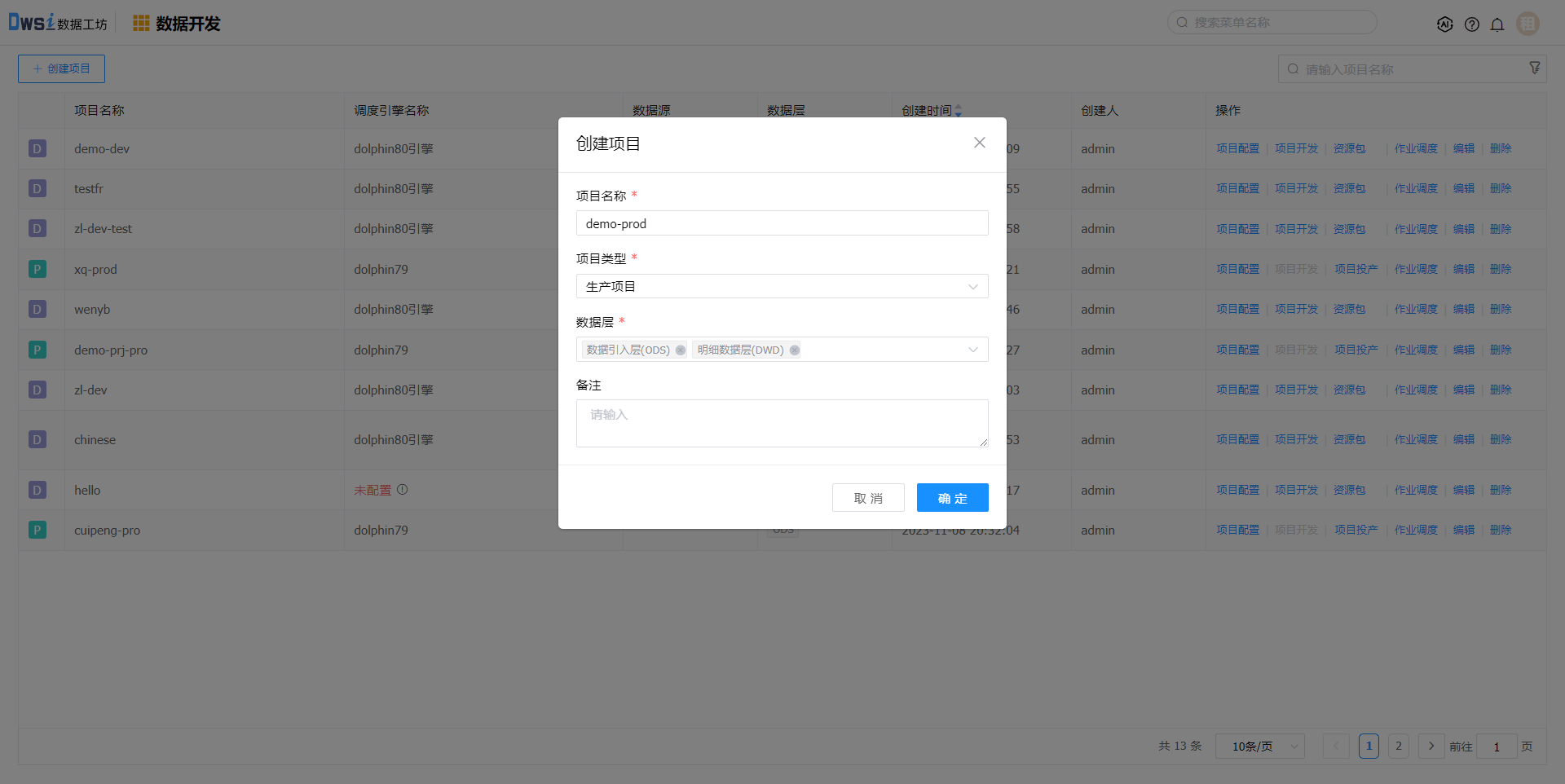
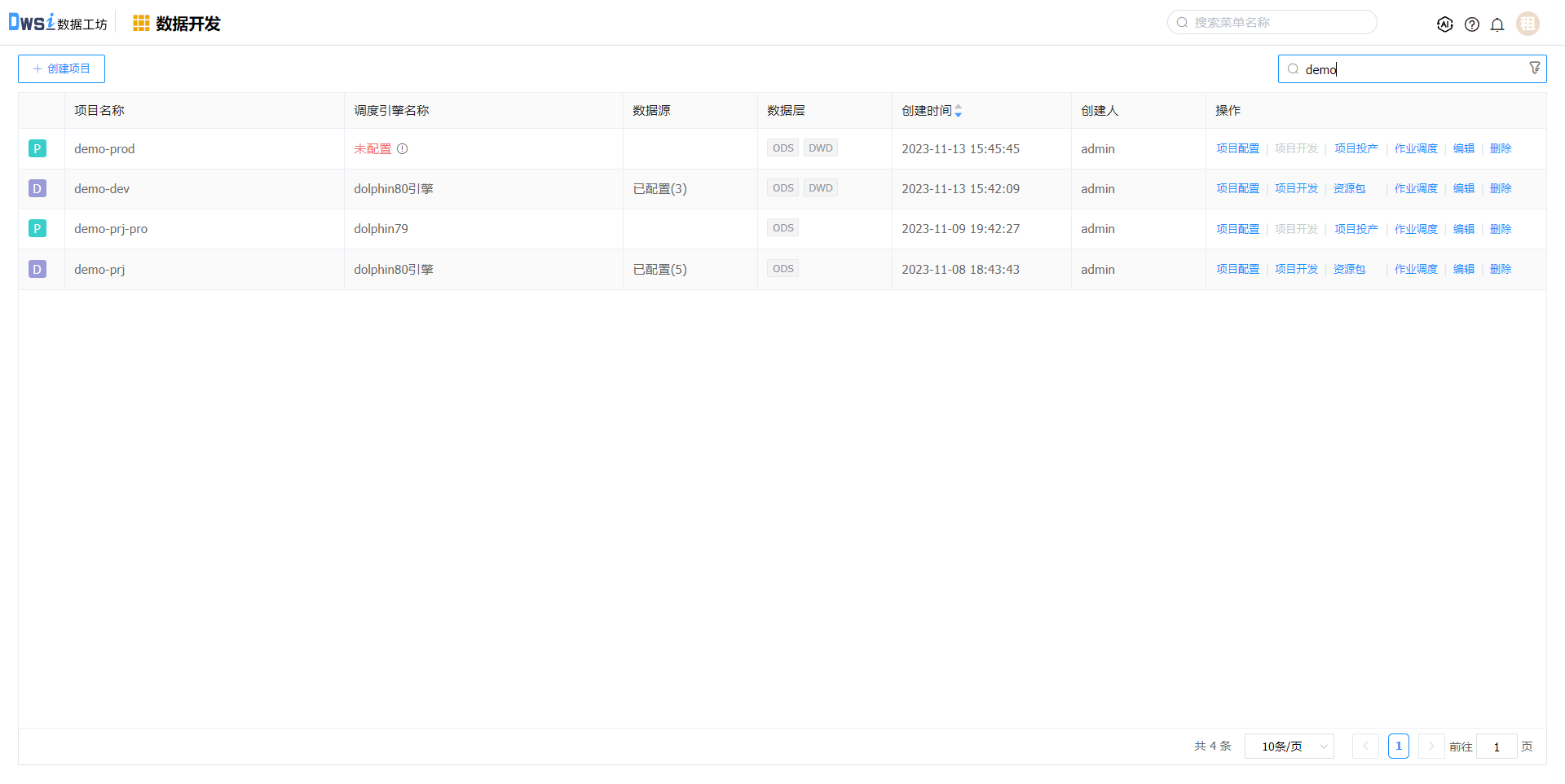
点击上方菜单栏“数据开发”,在【数据开发】页面,点击创建项目。
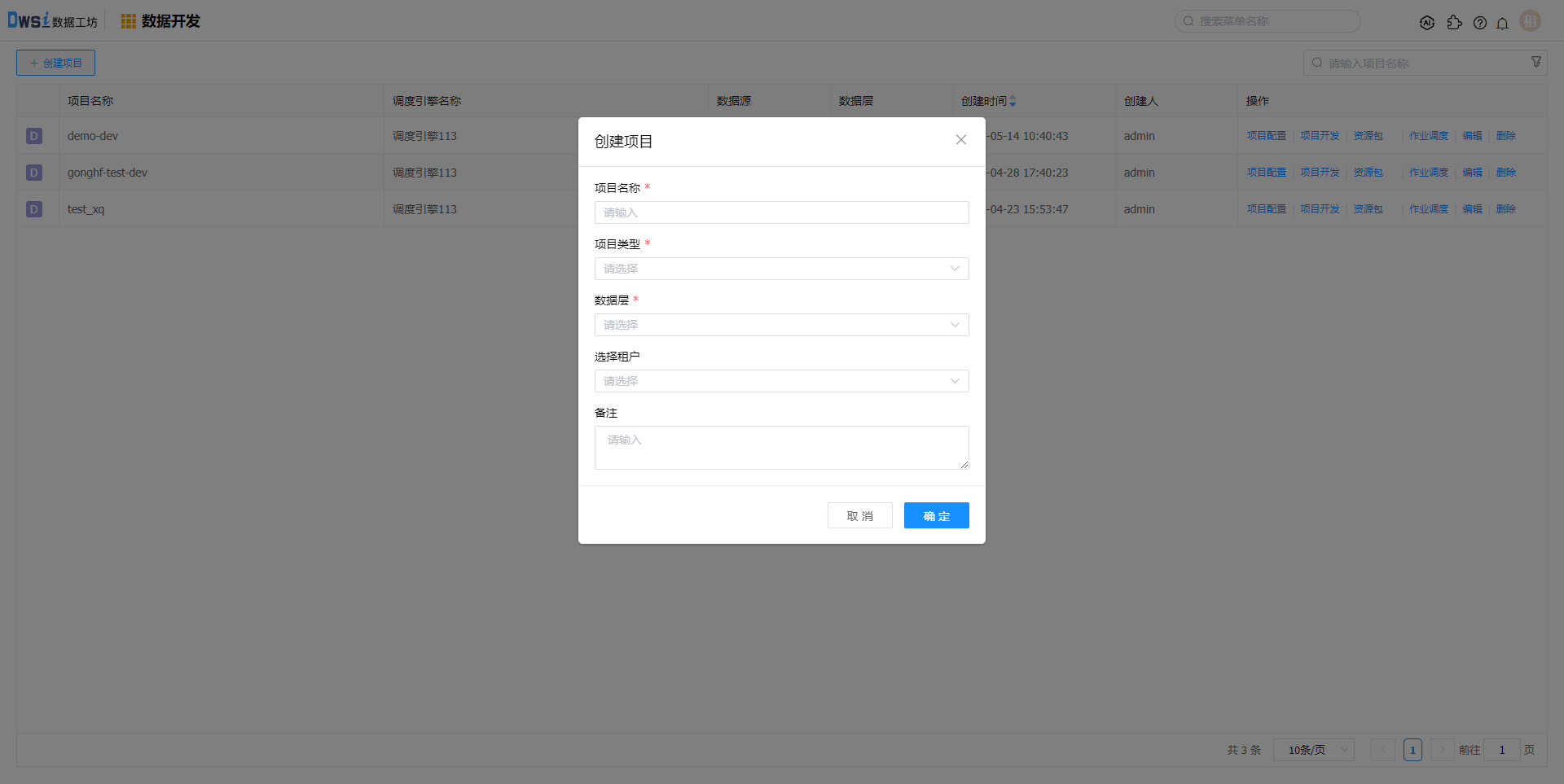
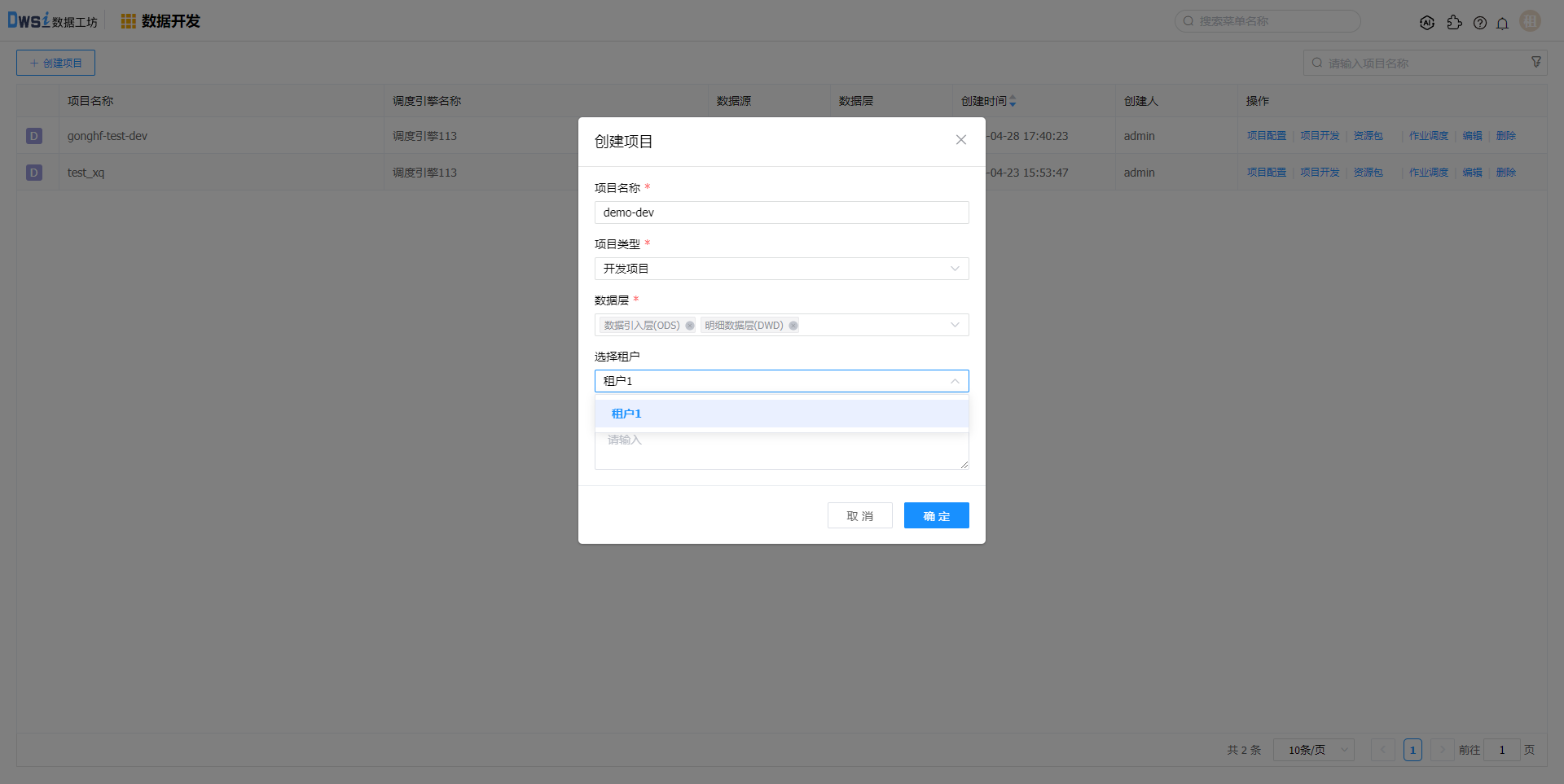
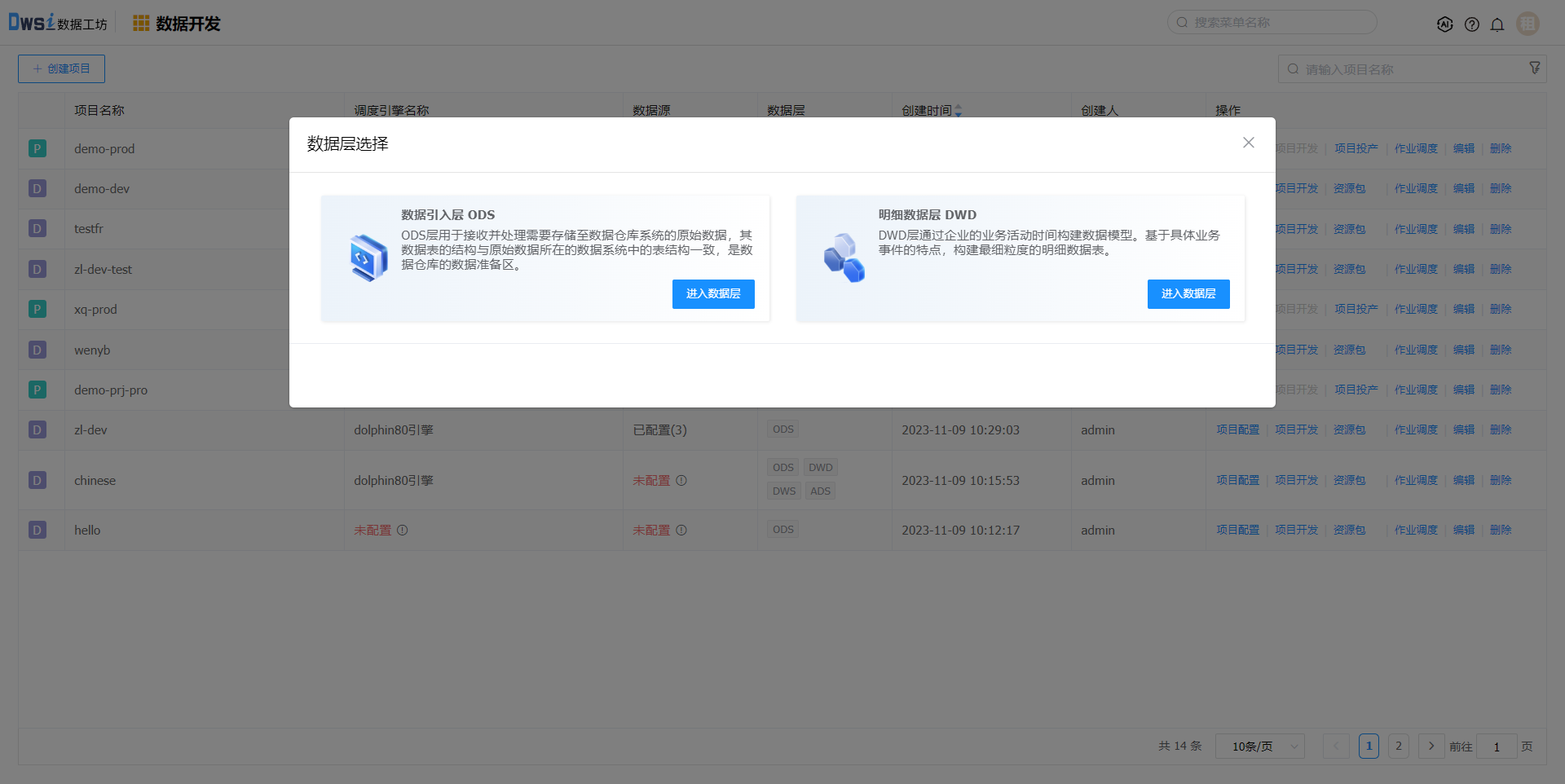
在创建项目页面,输入必填项,数据层选择ODS、DWD层。
本示例中创建的数据源分别属于ODS、DWD层,故该项目至少选择这两层
租户选择之前创建的租户,则该项目后续配置的调度引擎、成员和数据源资源均来源于该租户,未在该租户的资源无法选择。
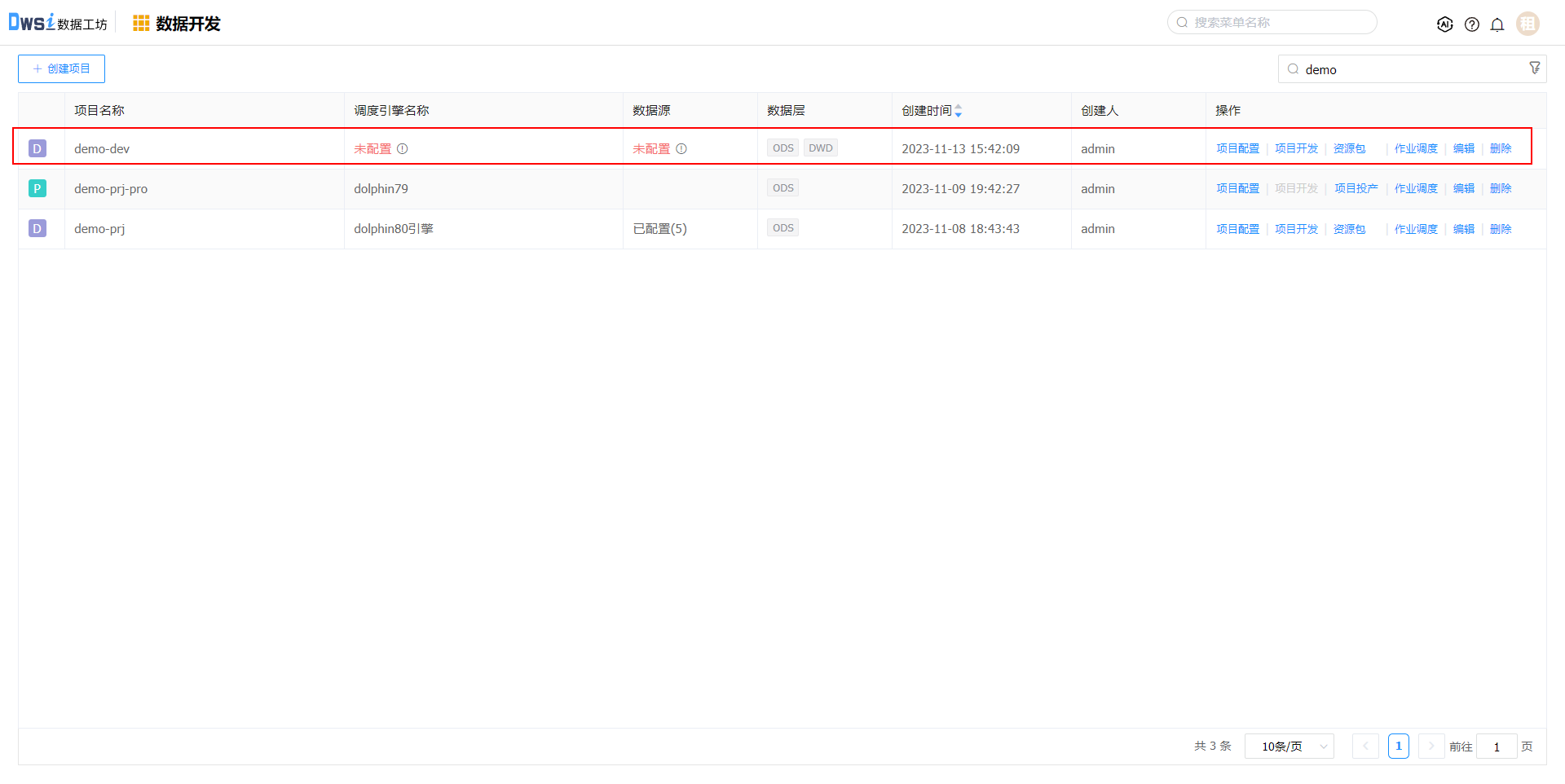
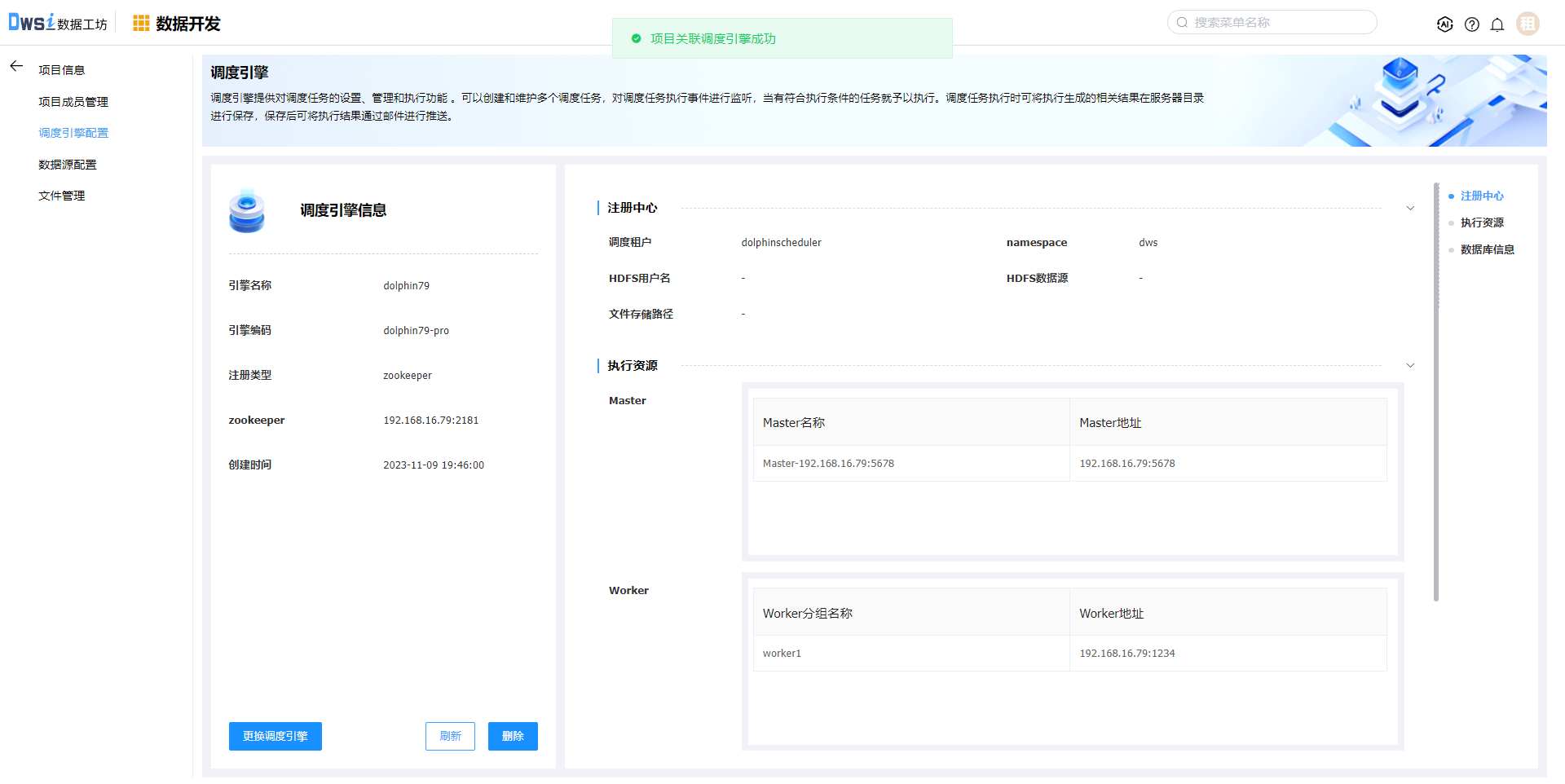
项目创建成功后,默认没有调度引擎及数据源,需要在【项目配置】中配置相关信息,点击项目配置操作。
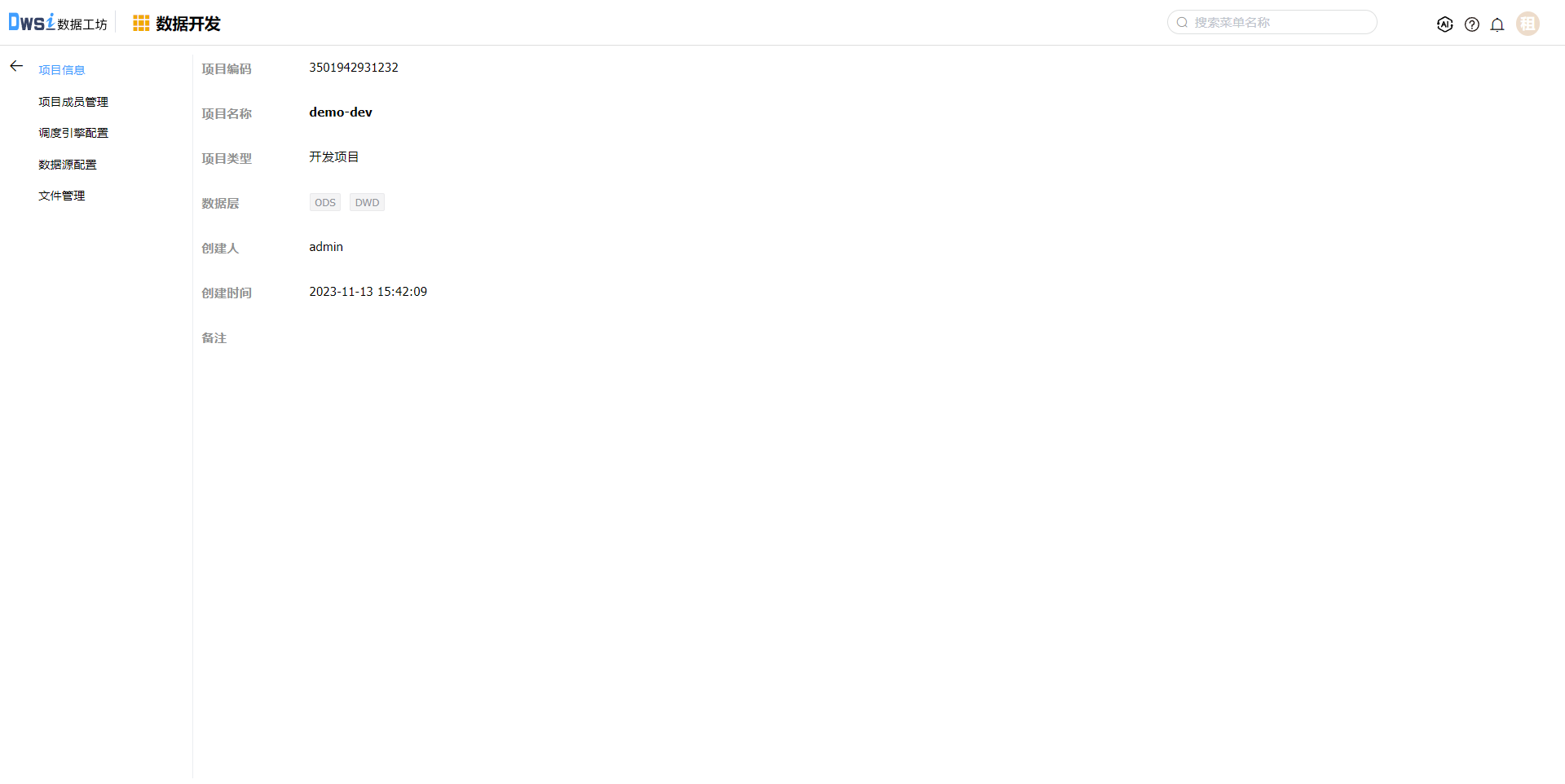
在项目配置中包含:项目信息、项目成员管理、调度引擎配置、数据源配置、文件管理。
项目成员管理,添加项目成员
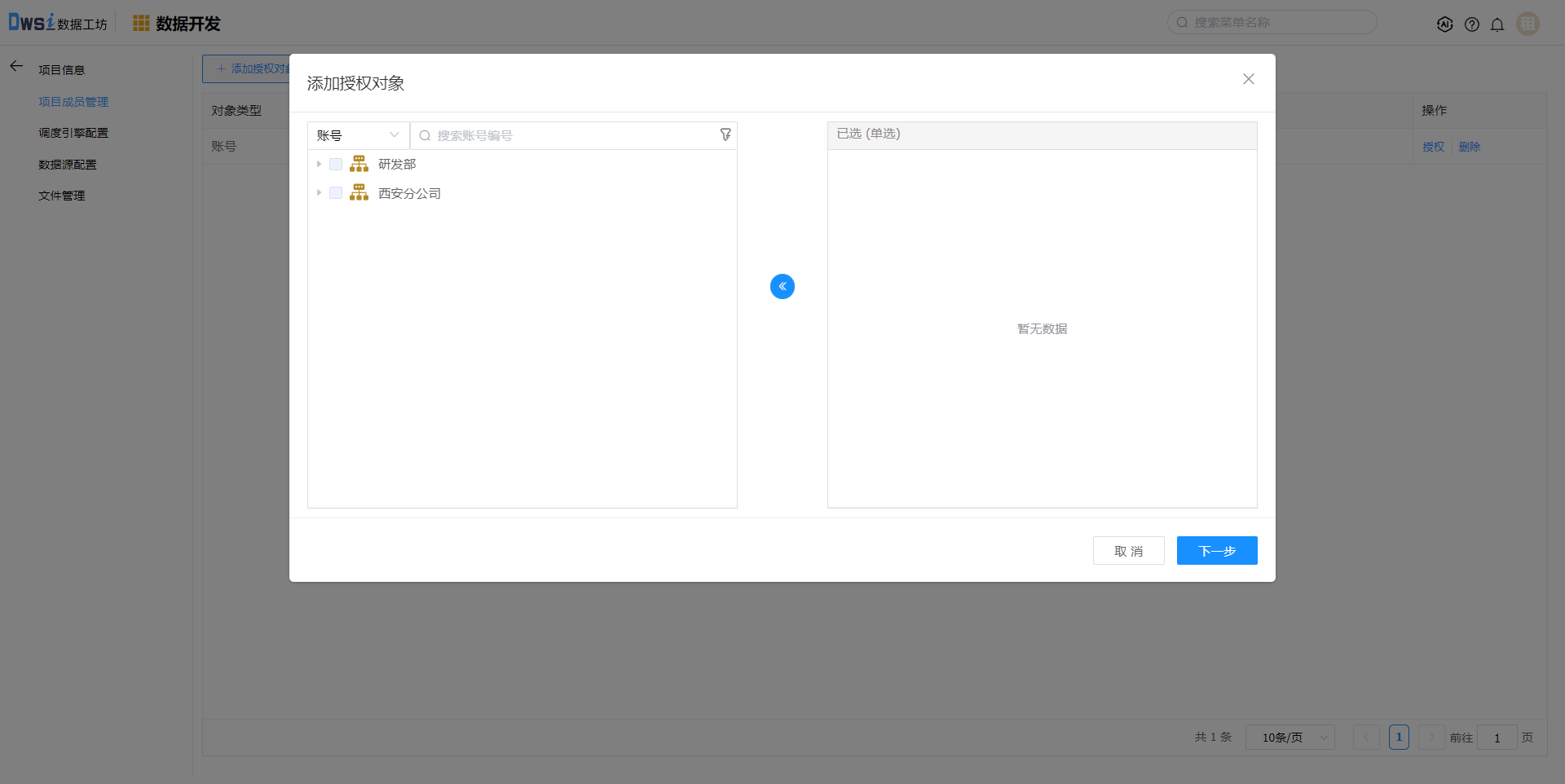
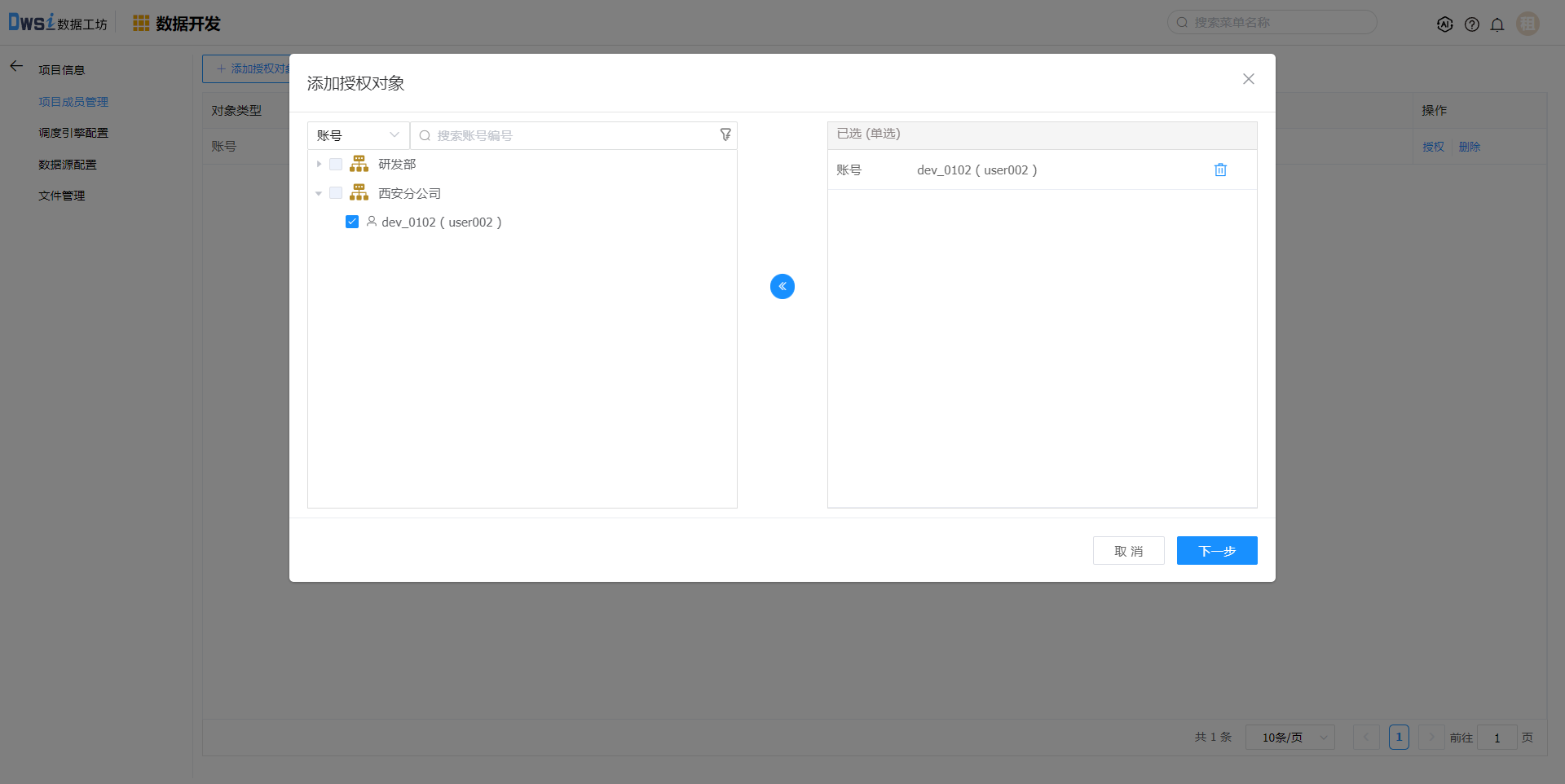
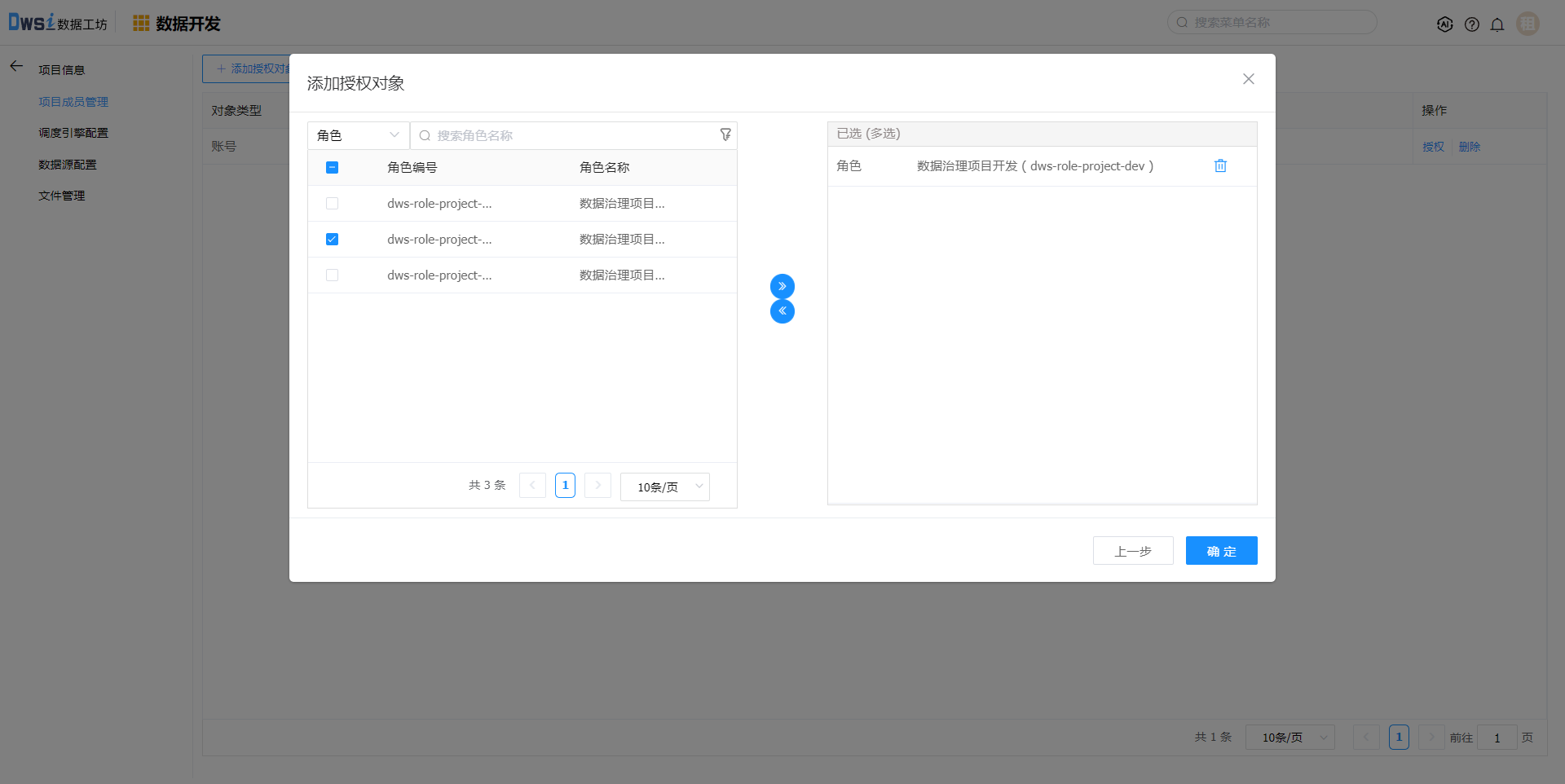
调度引擎管理,添加调度引擎
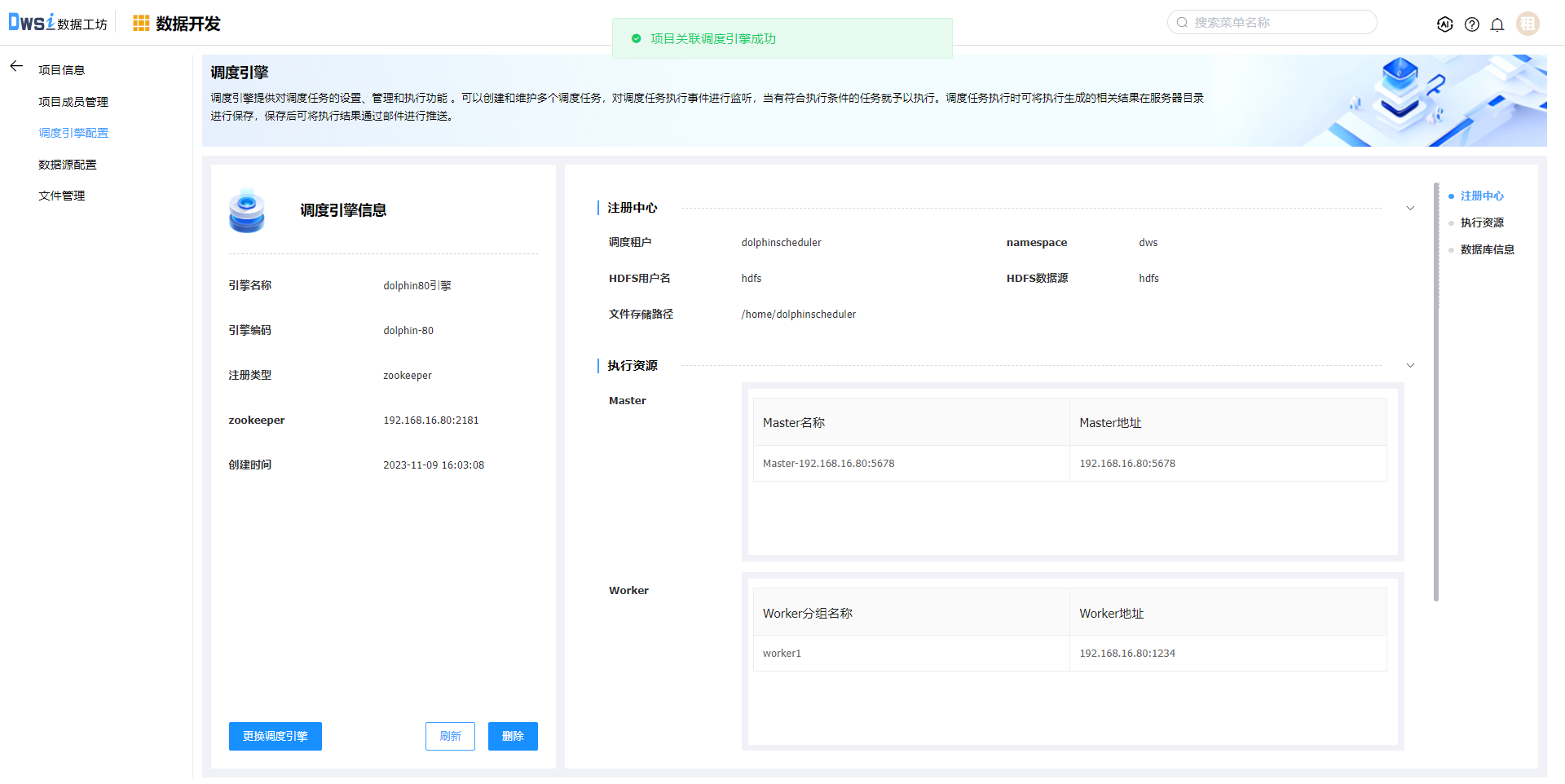
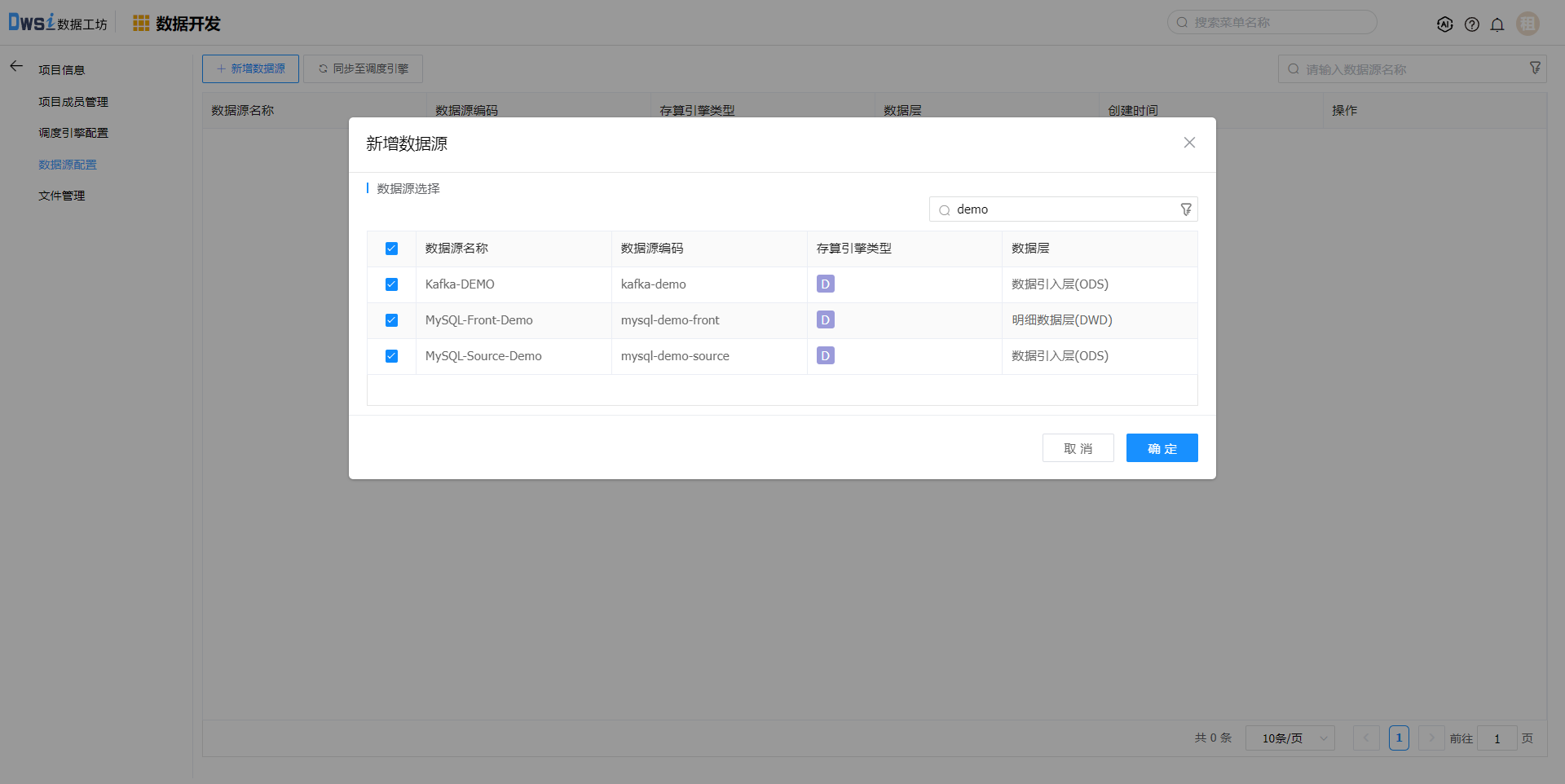
数据源管理,添加数据源
重复上述步骤,创建生产项目。
生产项目不需要配置数据源
# 2. 数据开发及调试
在【数据开发】页面中,点击开发项目的【项目开发】操作,选择ODS层,页面跳转到该项目ODS层的IDE开发页面。
# 开发批处理作业
以下示例创建模型为 原表同步到目标表。目标表已创建,但无数据。
在IDE中依次点击【集成作业】->【数据集成】,点击【数据集成】右侧的...,选择【新建数据集成作业】。
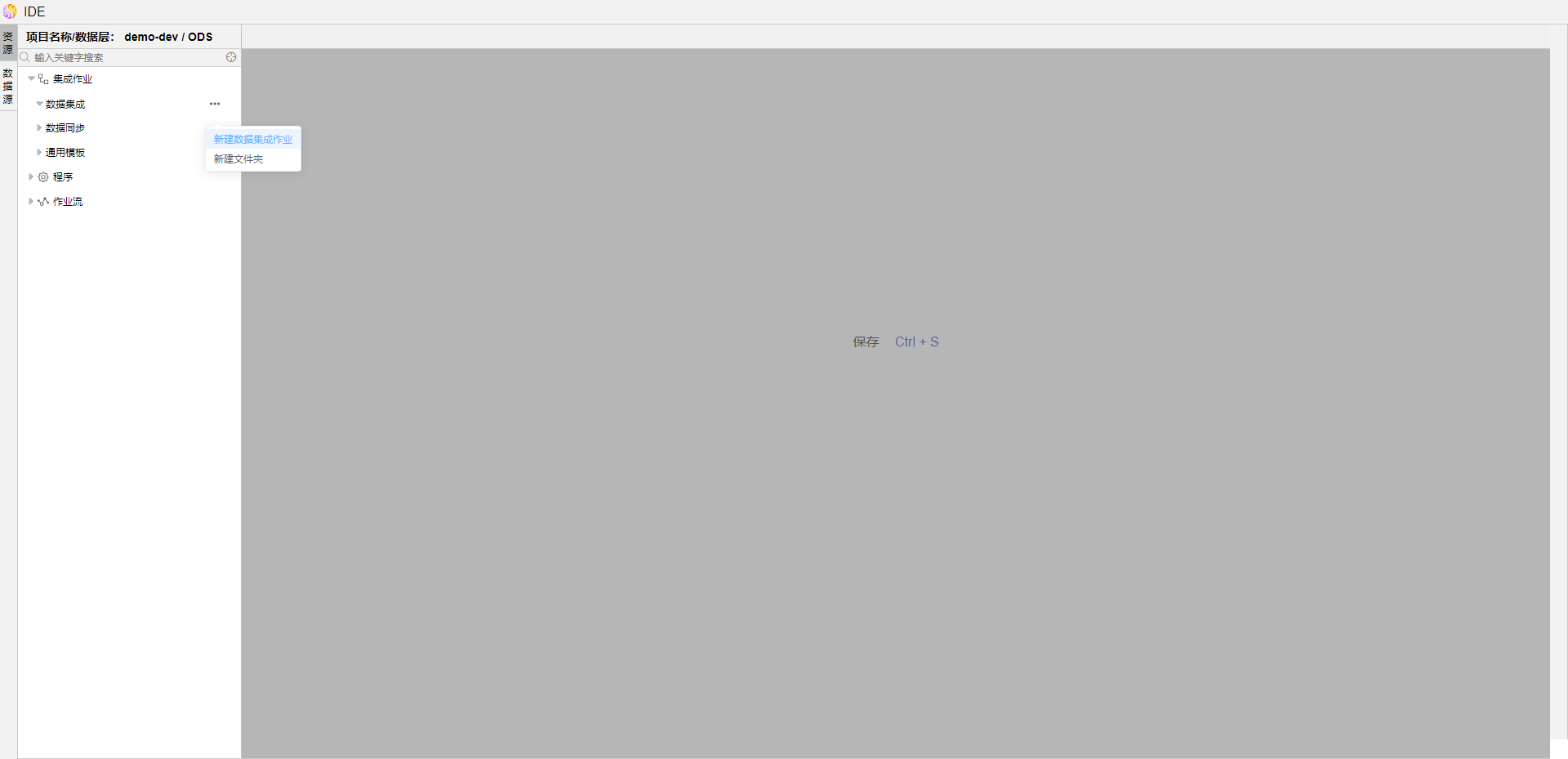
在弹出的【新建数据集成作业】页面,输入作业名称、选择作业类型为离线转换,点击确定按钮。
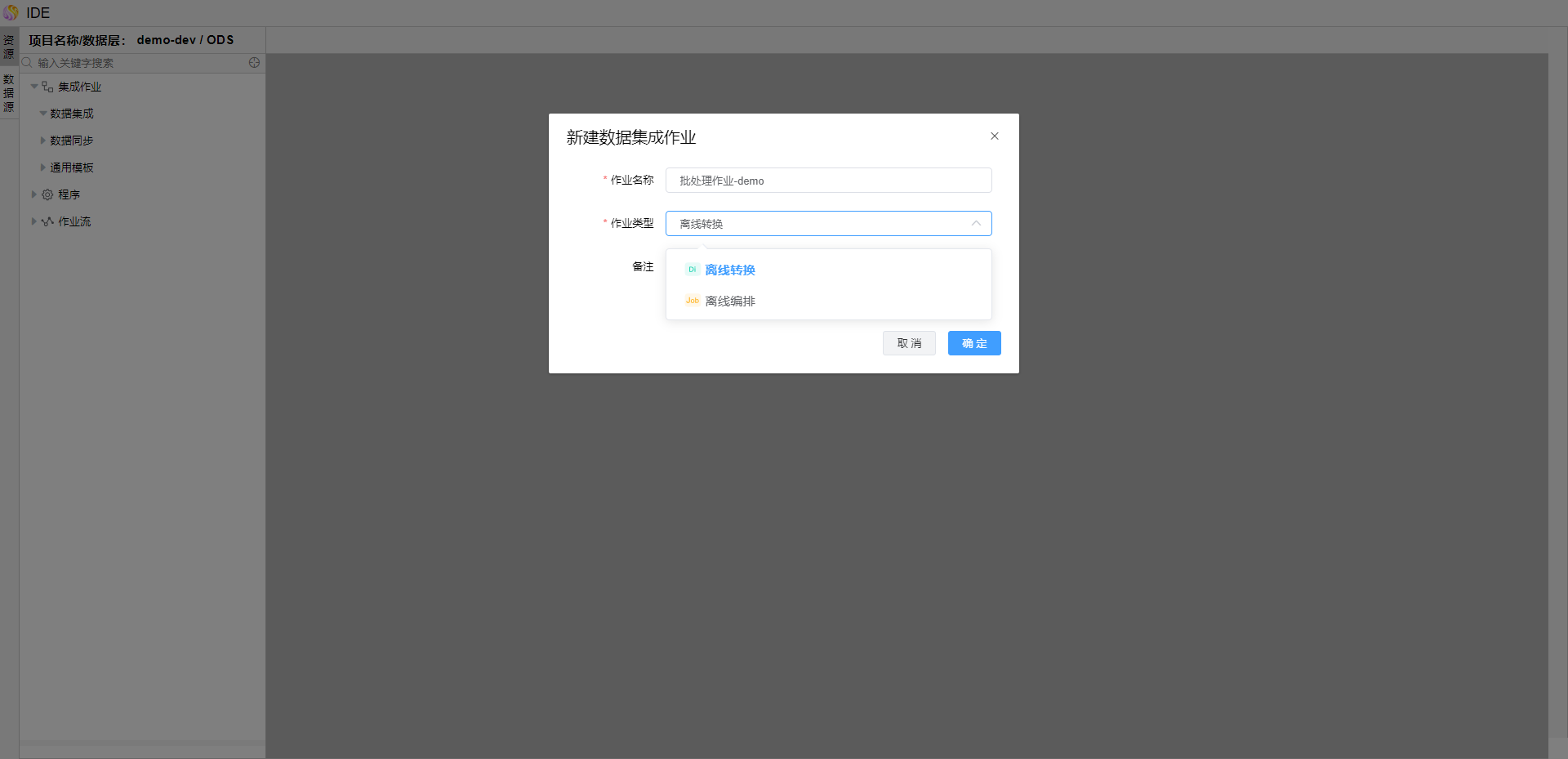
页面显示离线转换作业的初始化界面如下图。作业为转换作业的算子,右上侧有【通用配置】、【版本】、【草稿】,右上方有【运行】、【停止】、【保存】、【提交】操作按钮。
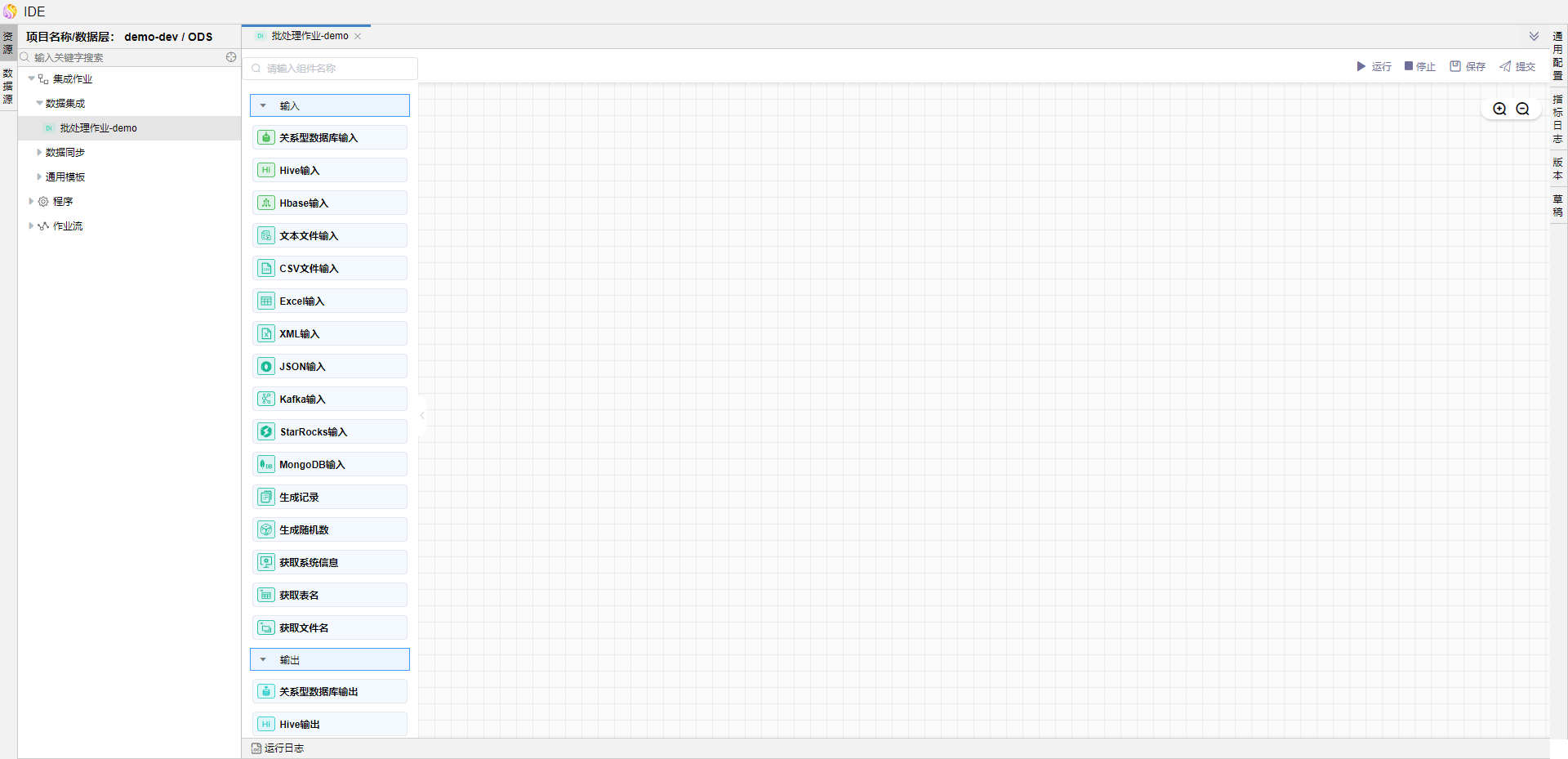
在左侧算子中拖拽【关系型数据库输入】、【关系型数据库输出】算子
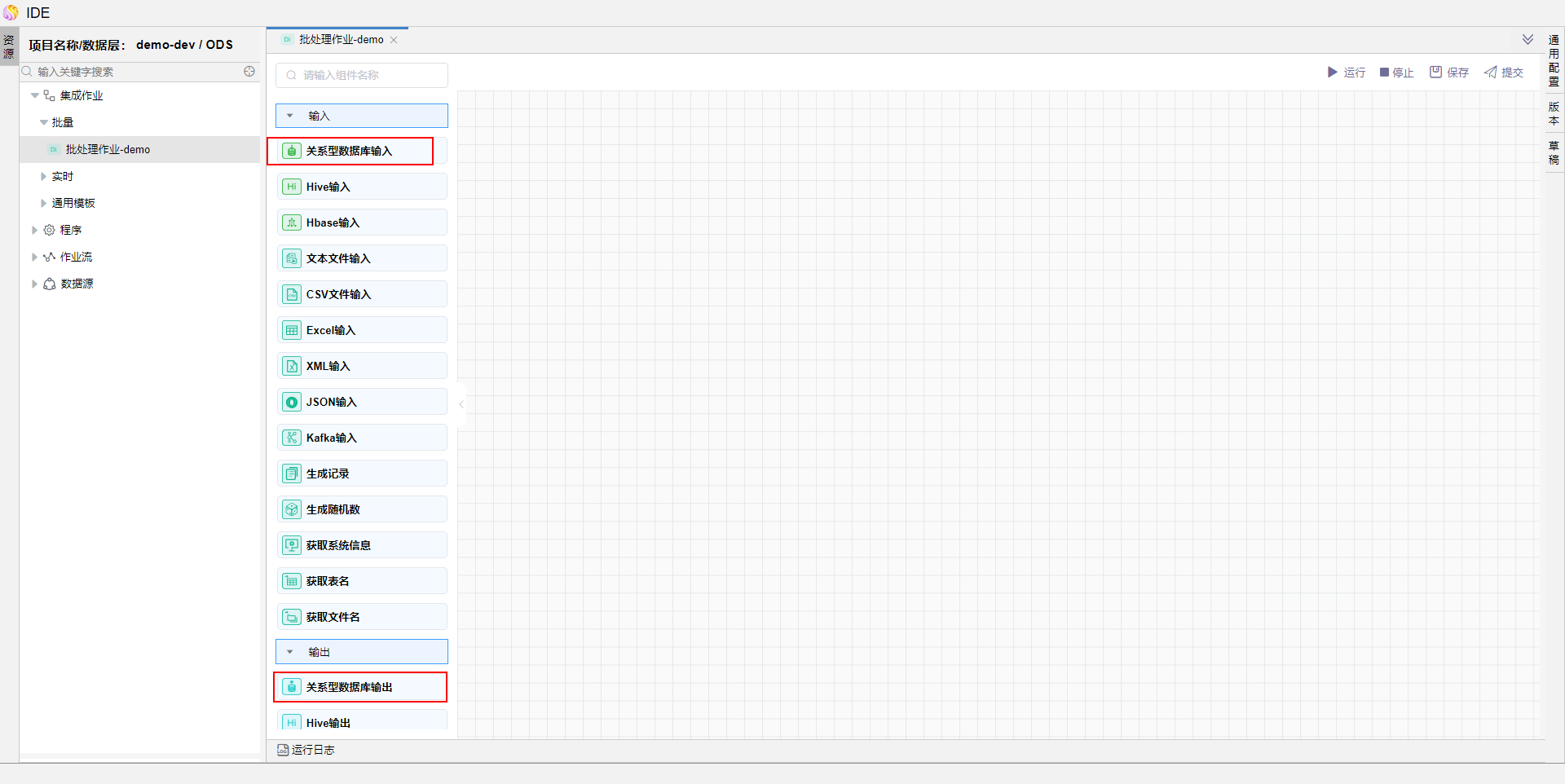
在已拖拽到画布中的【关系型数据库输入】中移动鼠标至图中位置,拖拽连线指向【关系型数据库输出】。
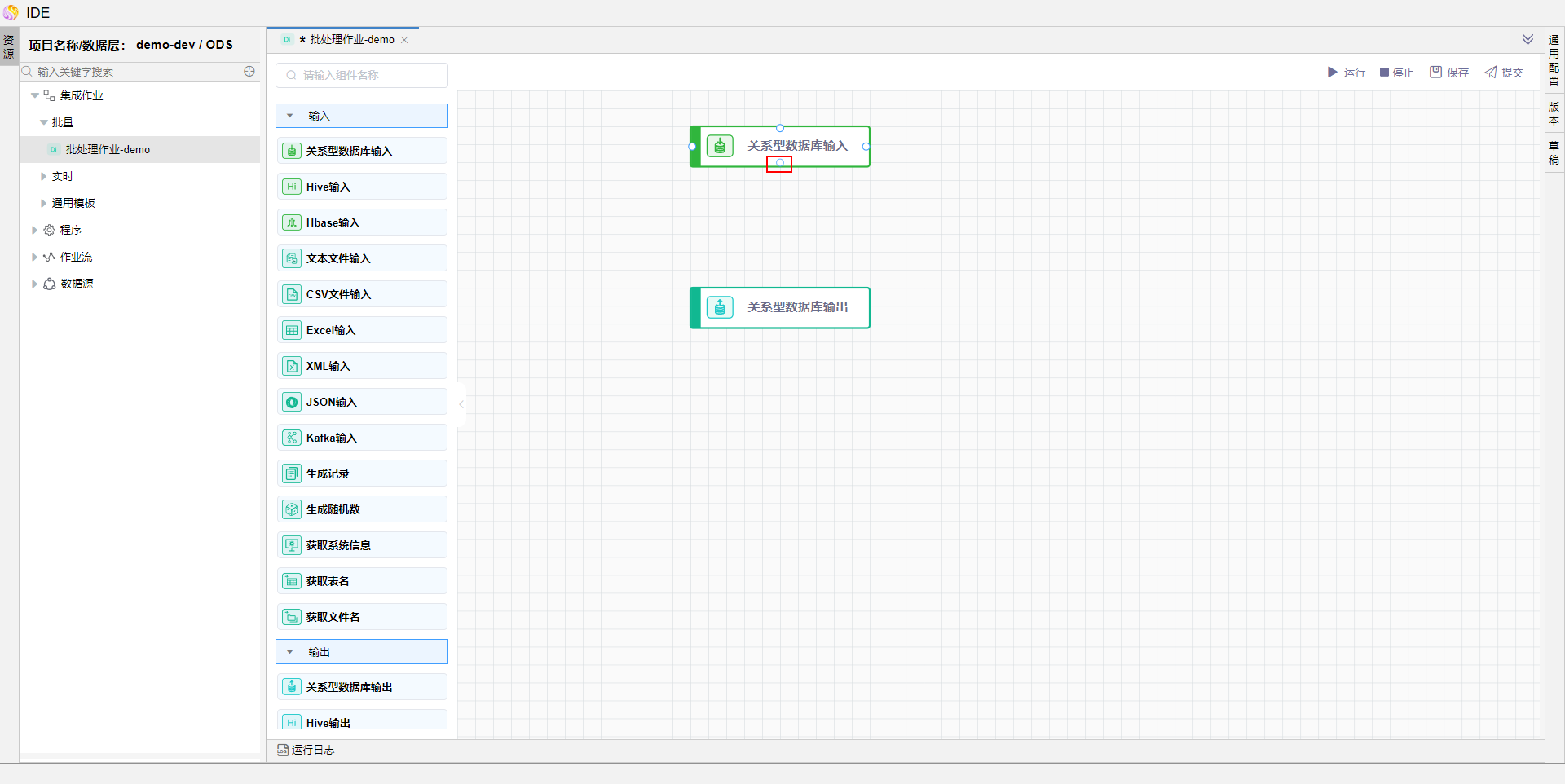
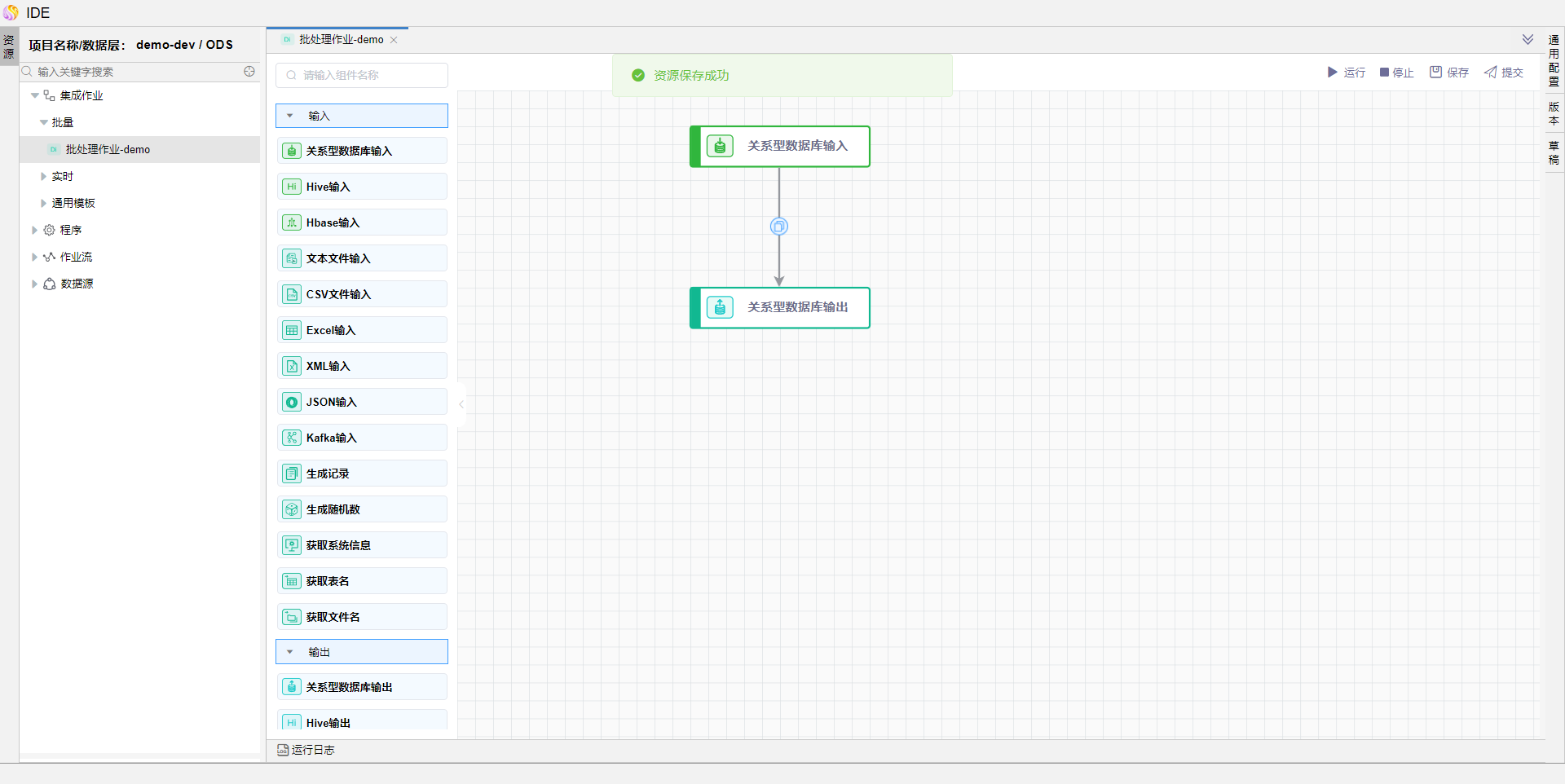
连线完成后的模型如图
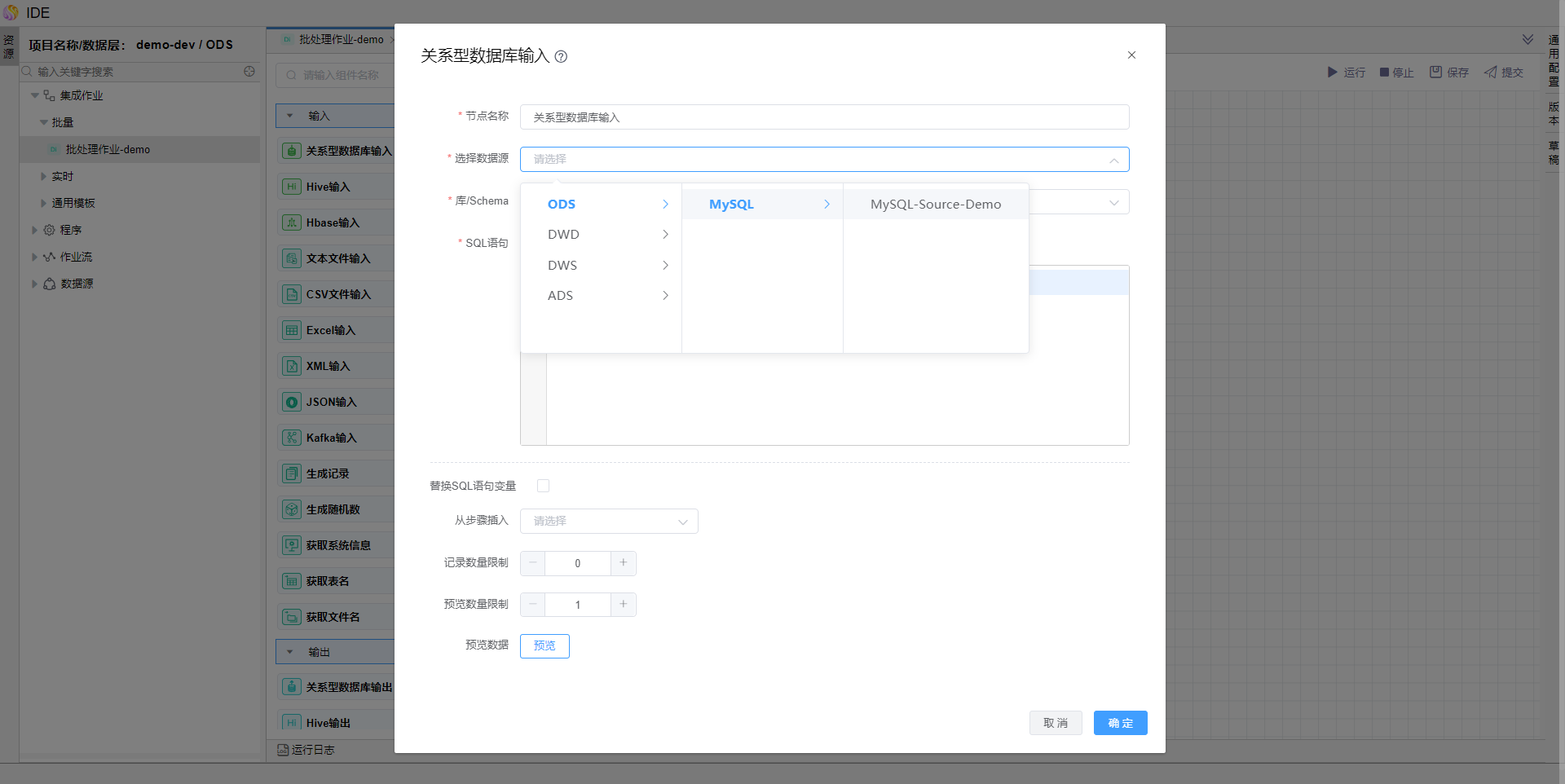
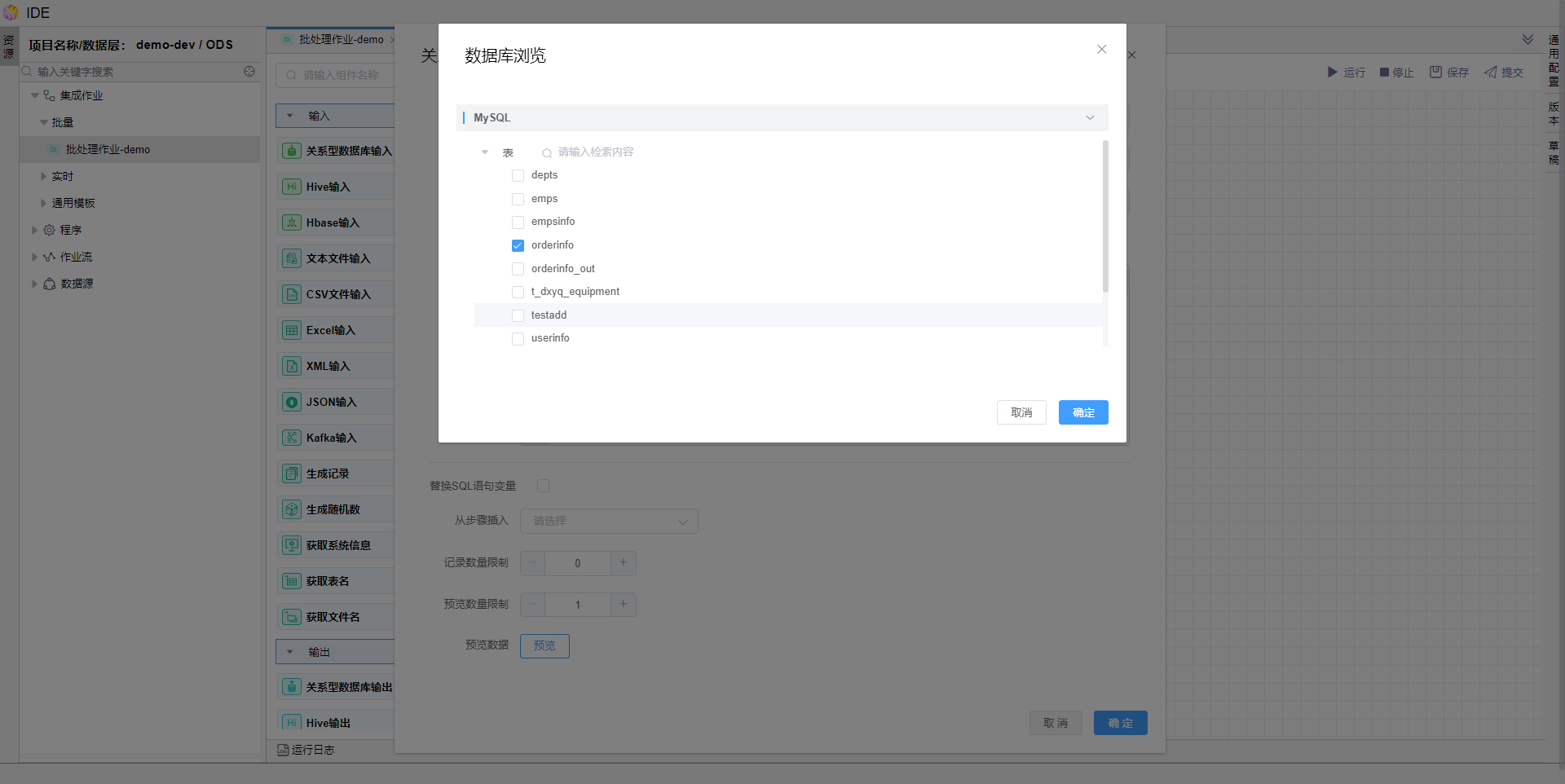
编辑【关系型数据库输入】算子,选择数据源及获取SQL查询语句。
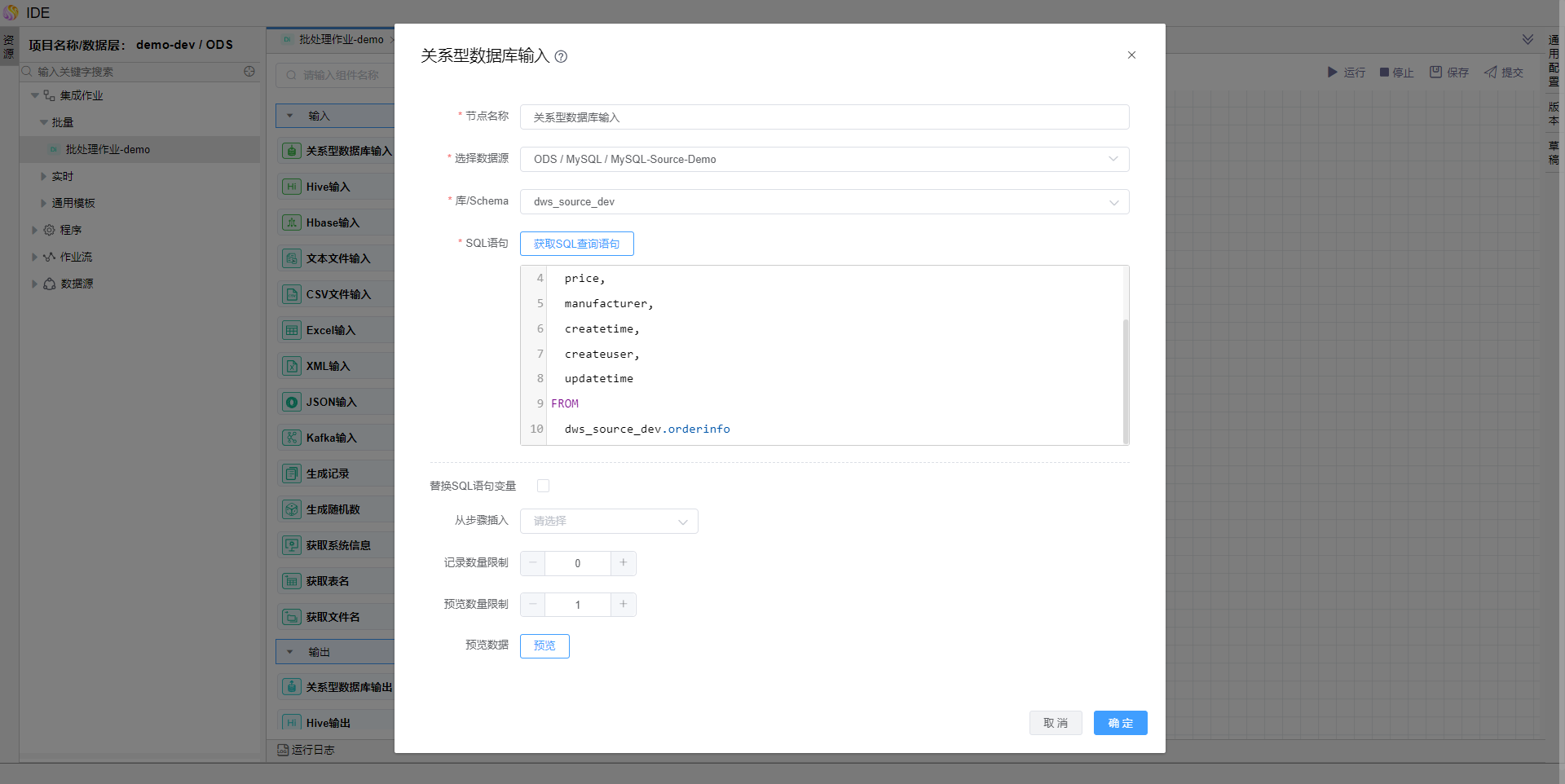
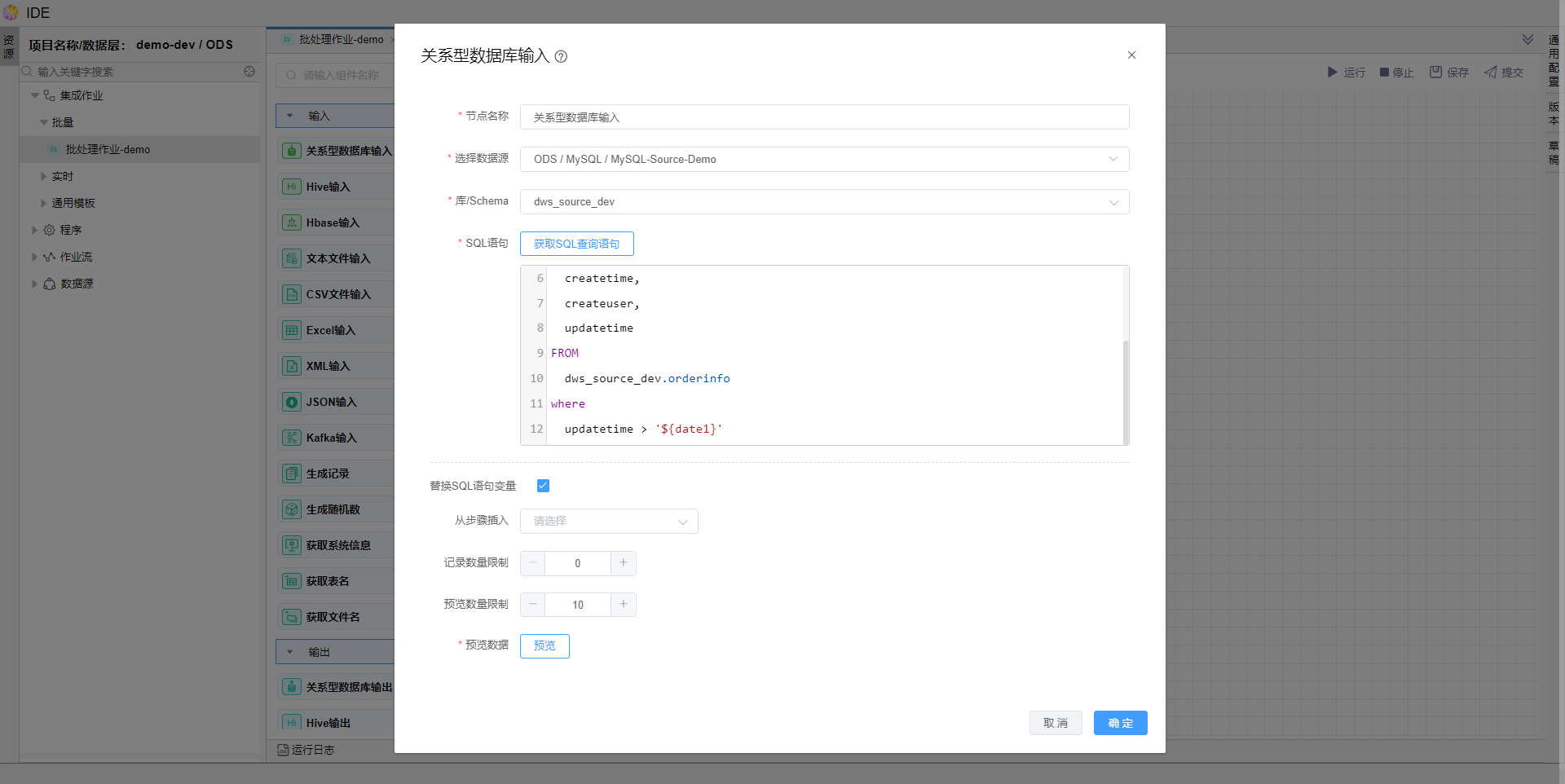
编辑sql语句,增加查询条件,条件使用变量传值;并勾选【替换SQL语句变量】。
编辑【关系型数据库输出】算子,选择数据源、库及表,并勾选【truncate表】、【指定数据库字段】。
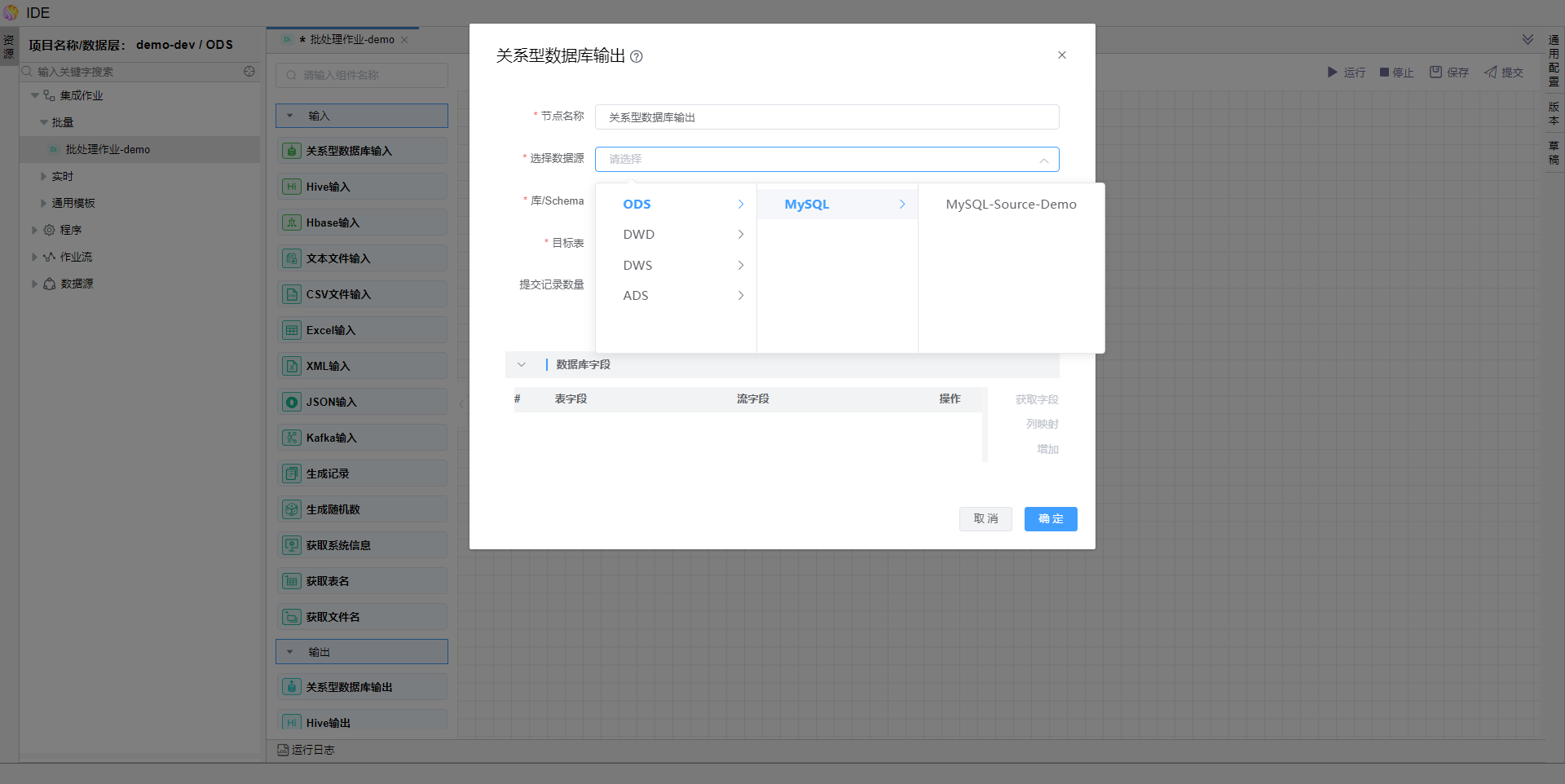
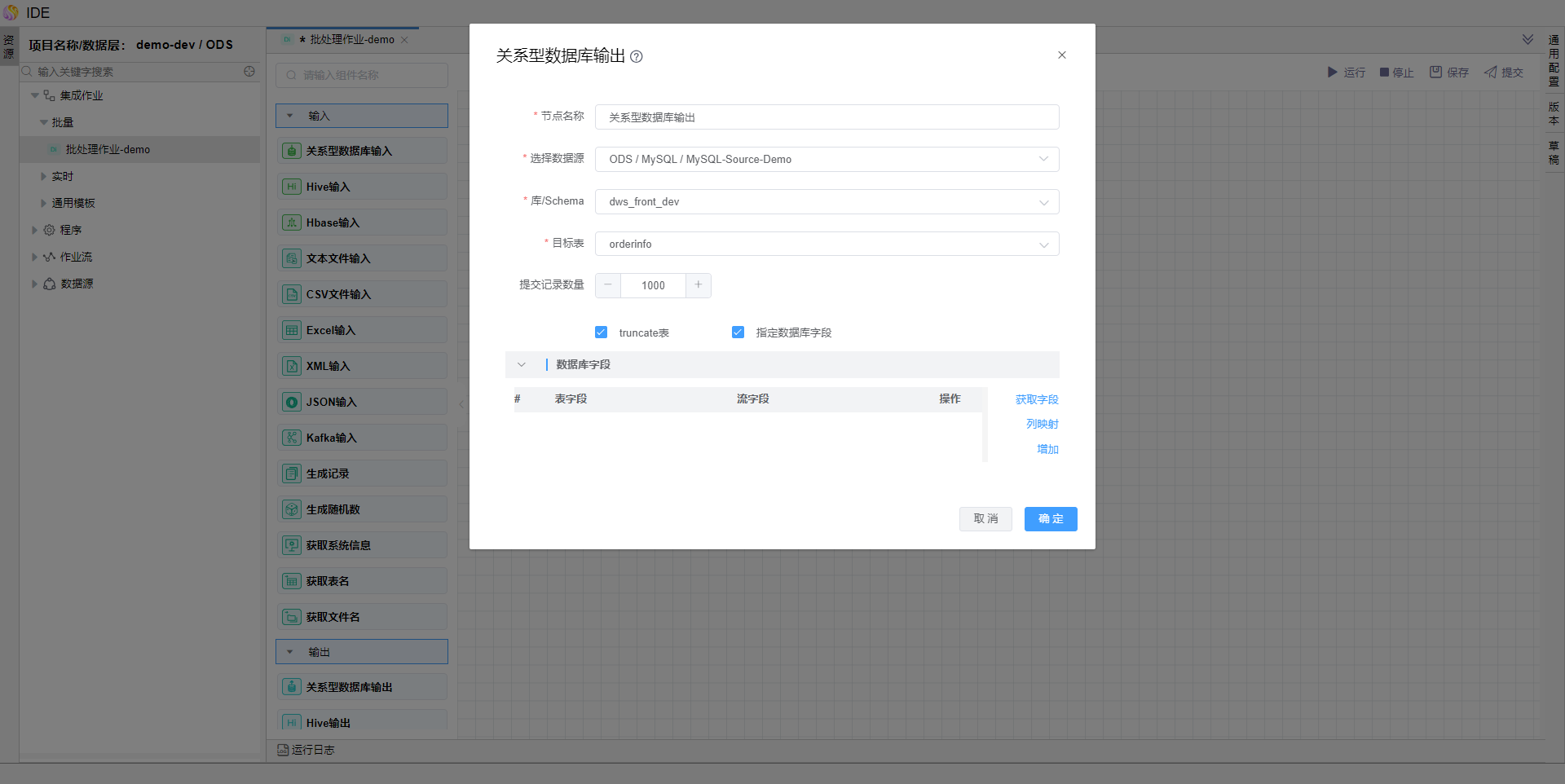
点击【获取字段】
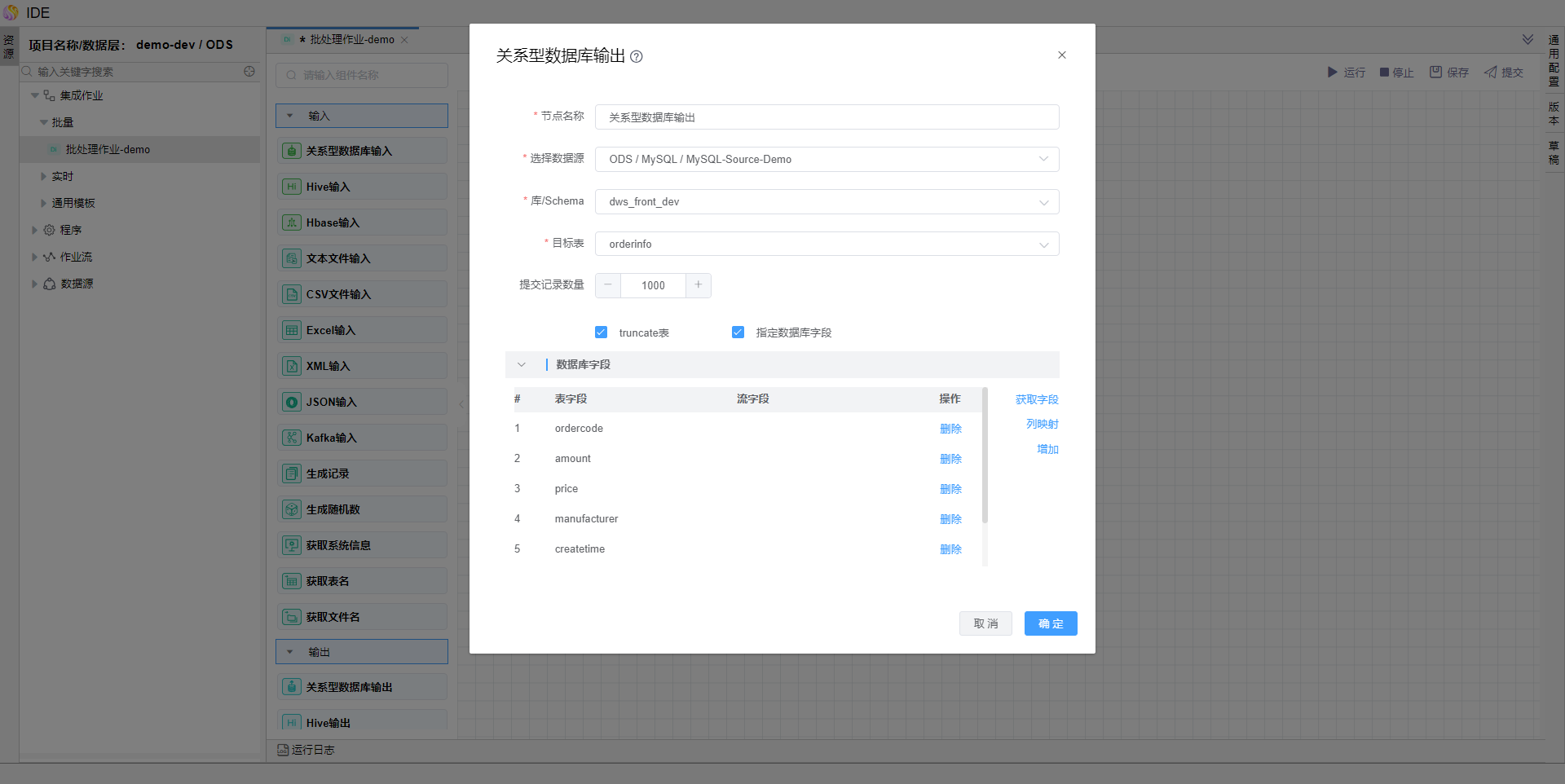
点击【列映射】
同名字段可以自动映射,不同名字段可手动选择,点击添加到映射结果中。
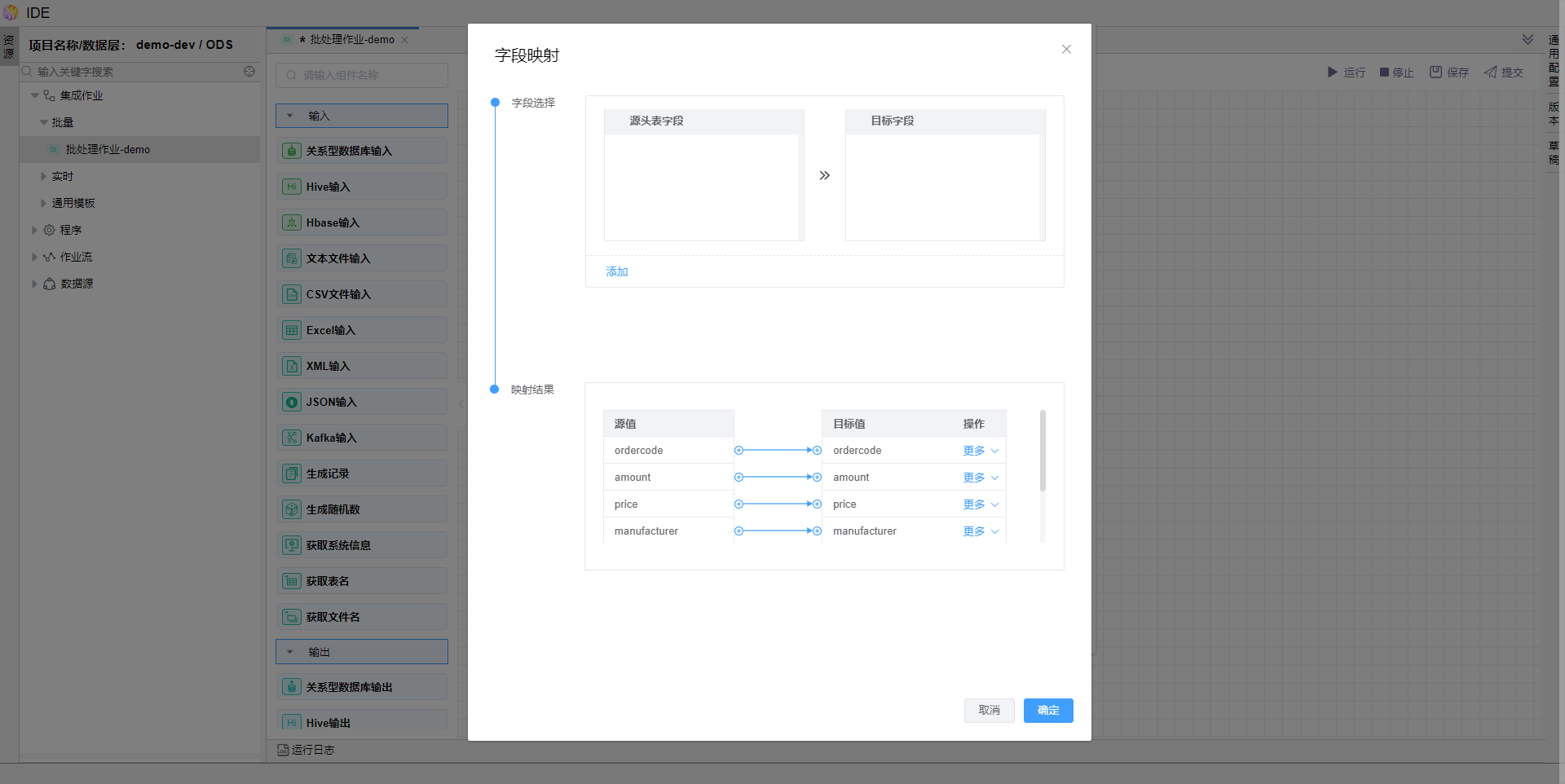
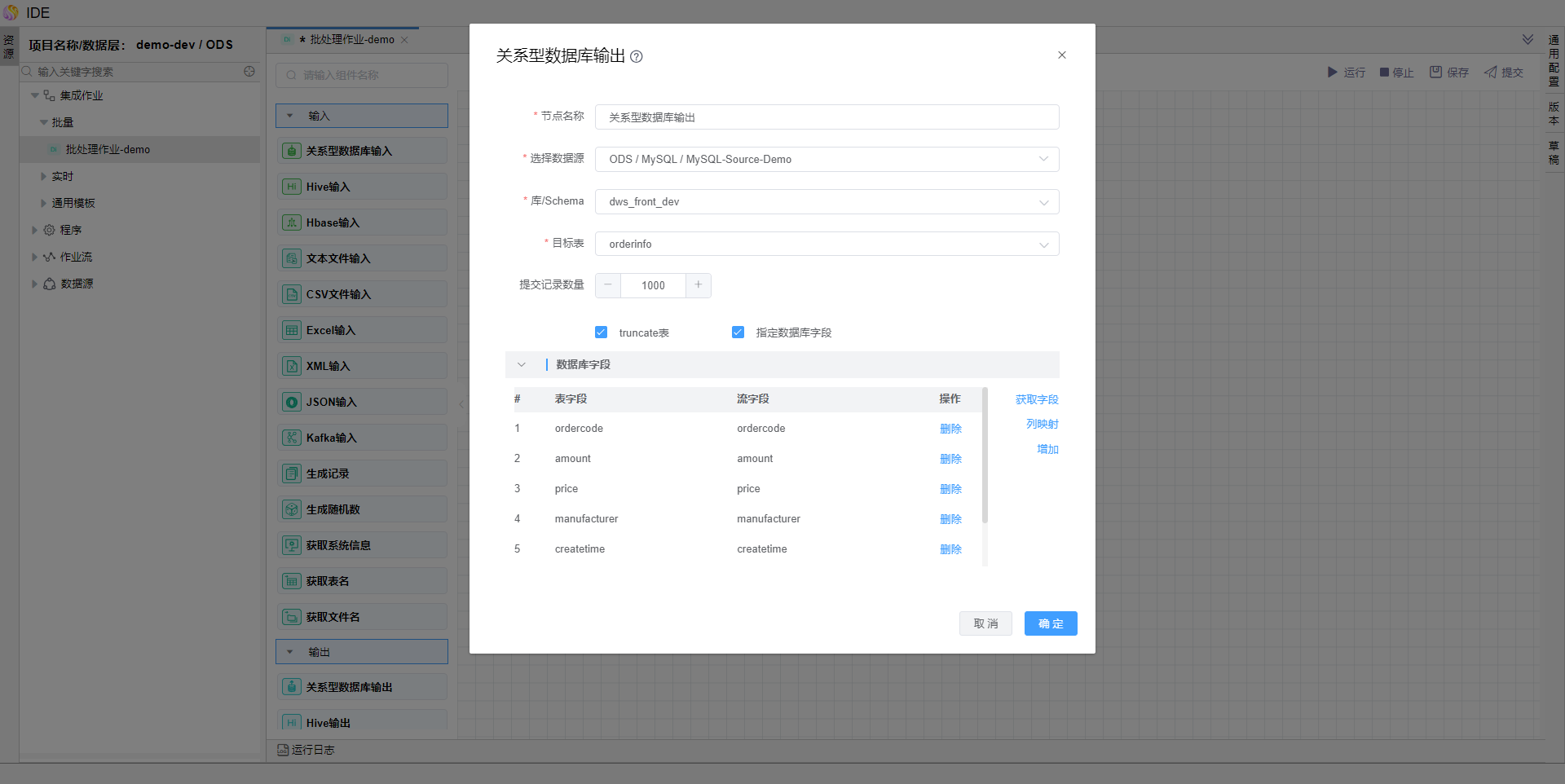
点击【确定】按钮,保存模型
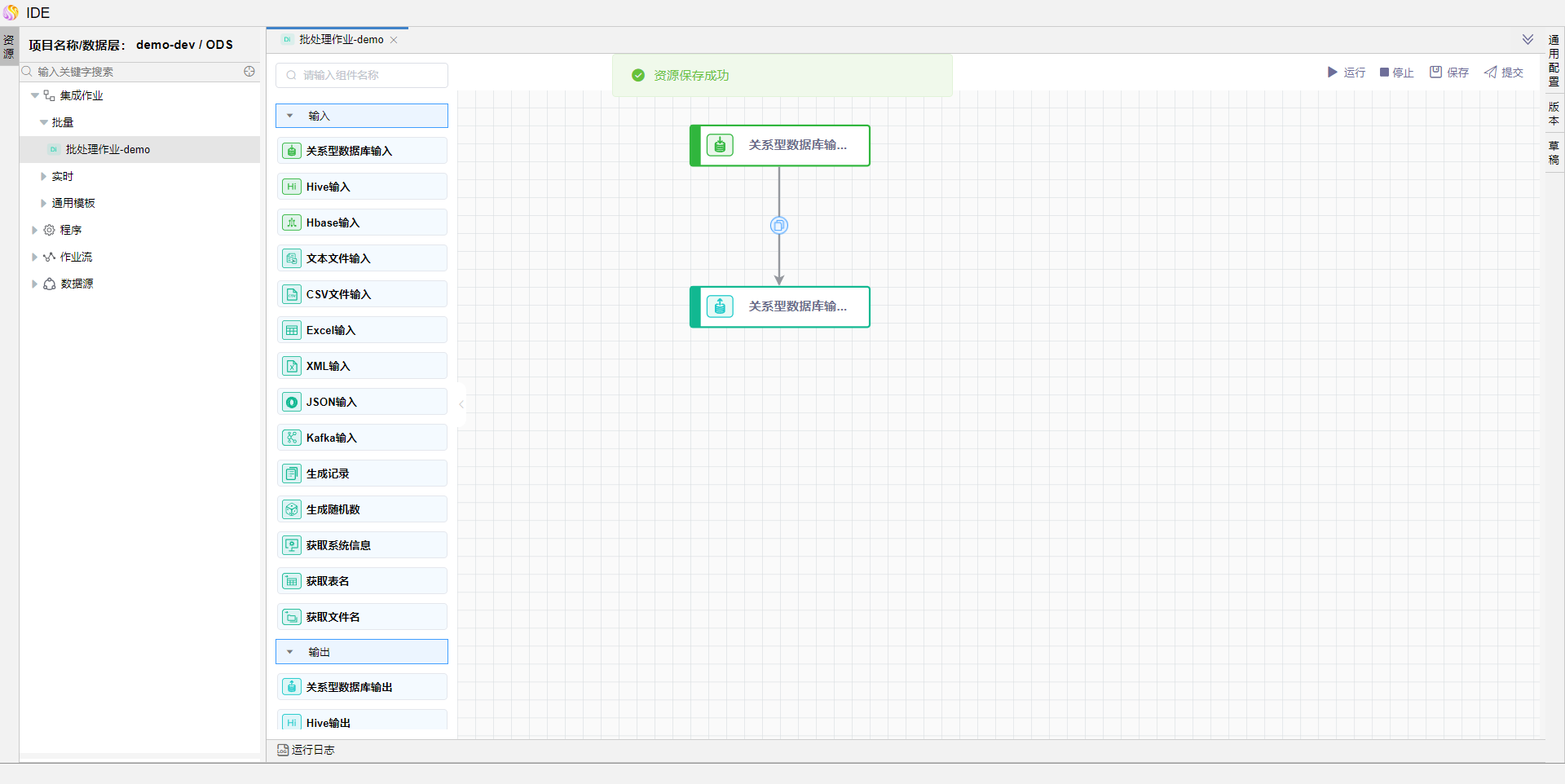
点击右侧【通用配置】,在命名参数中增加参数 date1,并点击确定保存。
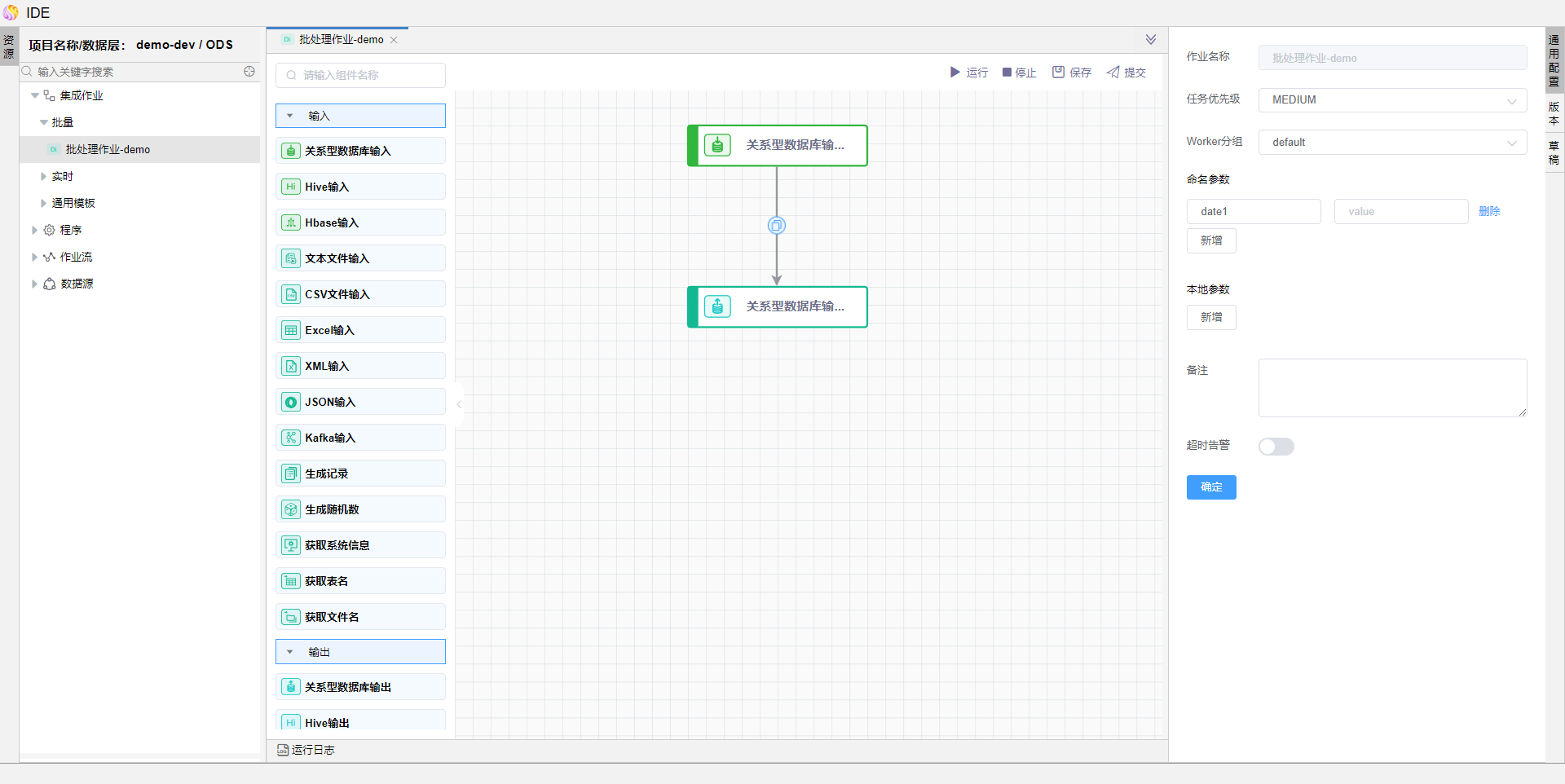
点击右上方的【运行】按钮,在弹出的运行窗口中输入参数值,如2019-01-01。
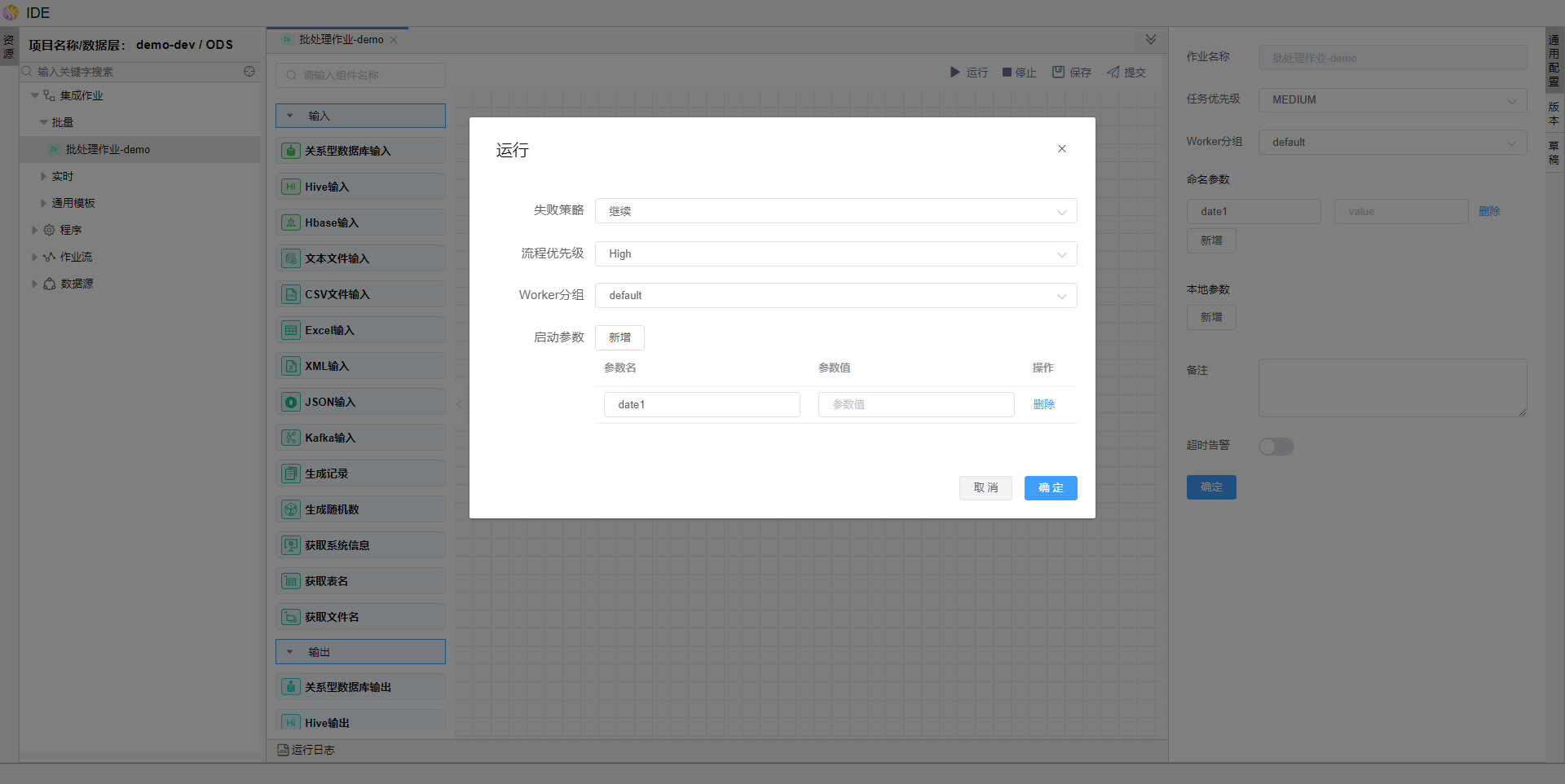
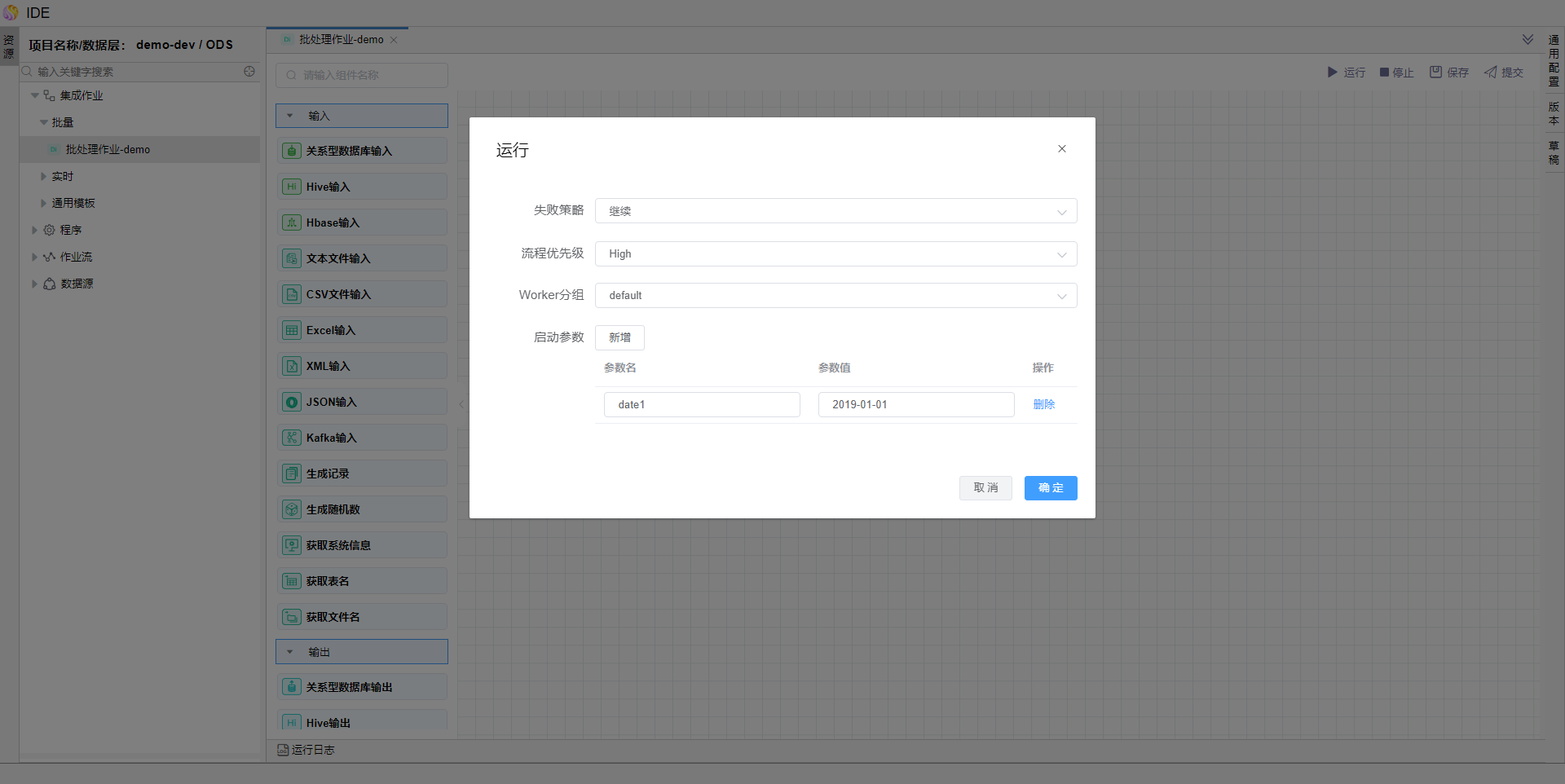
点击确定按钮,批量作业可运行依次,调试查看是否运行成功。
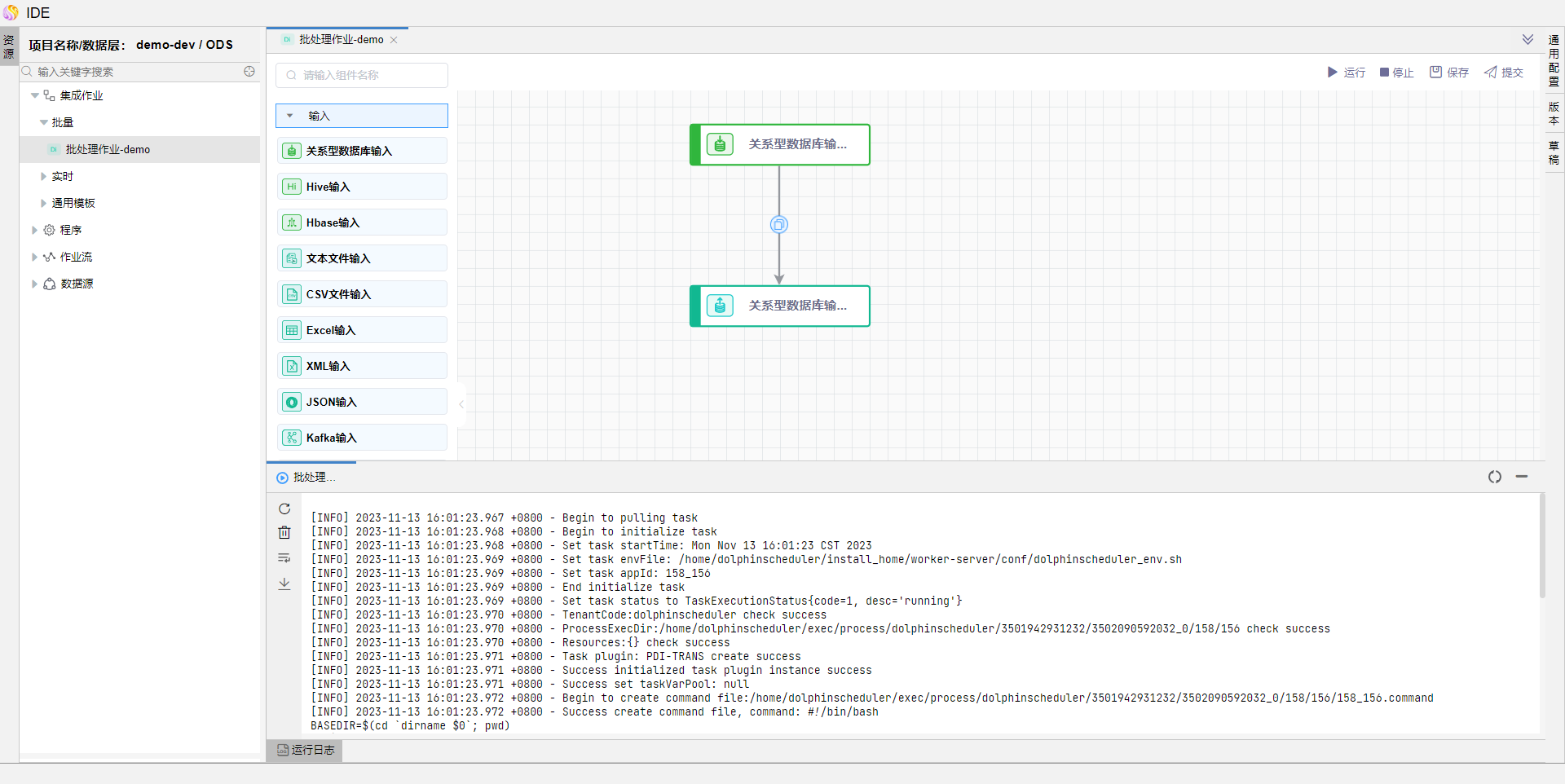
当作业运行状态如下图,则代表作业成功运行结束。
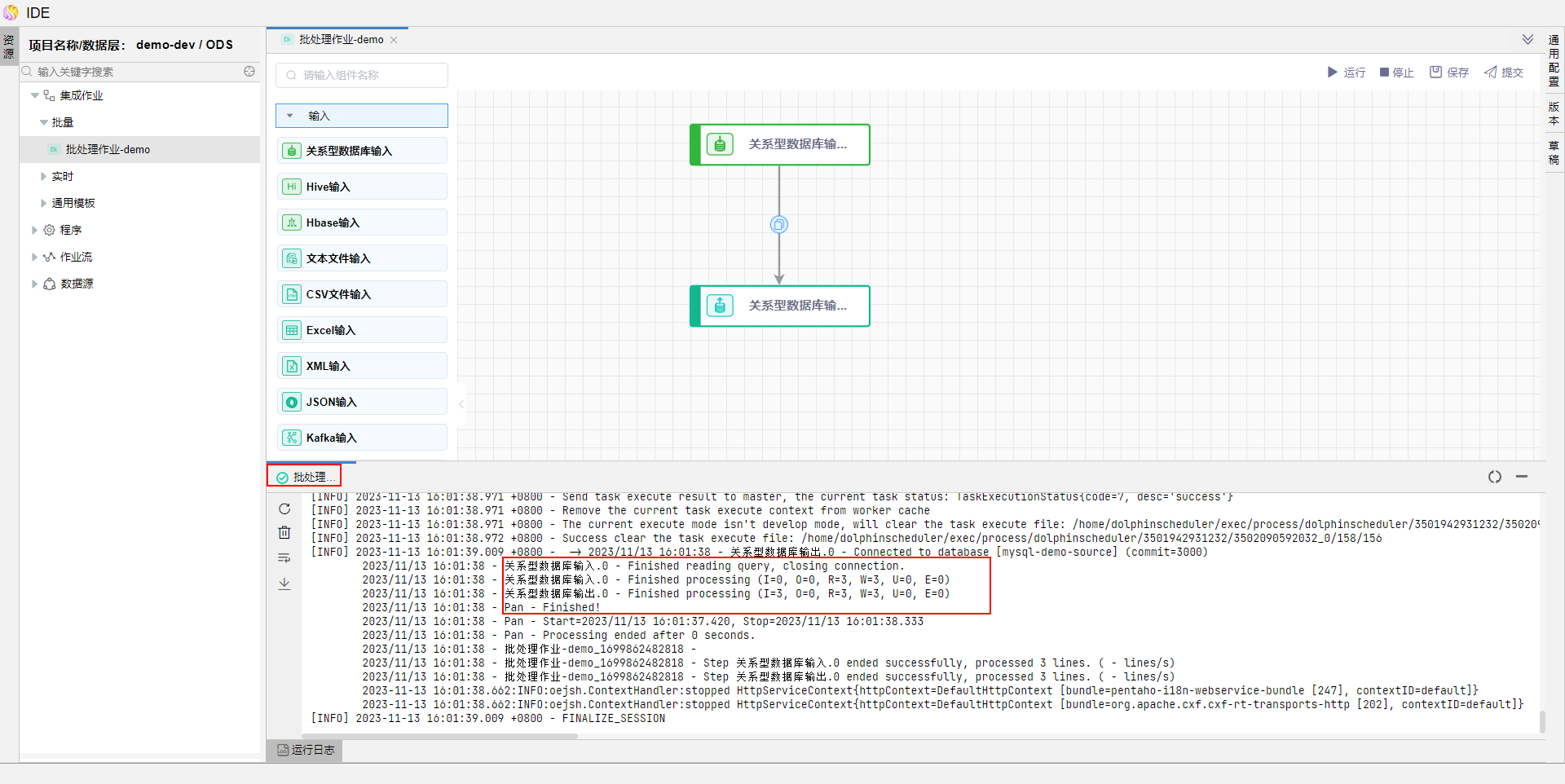
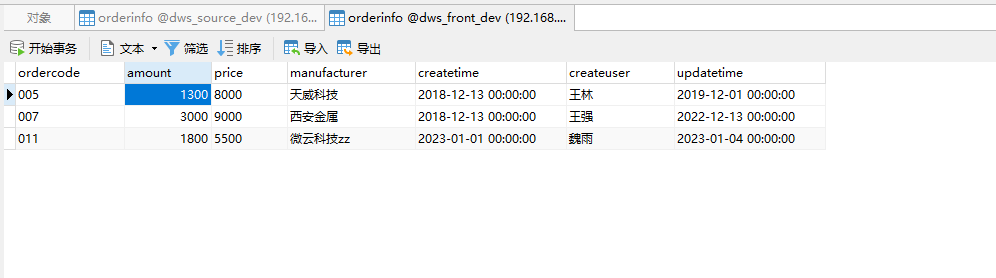
查看目标库中数据成功入库。
# 开发流作业(实时作业)
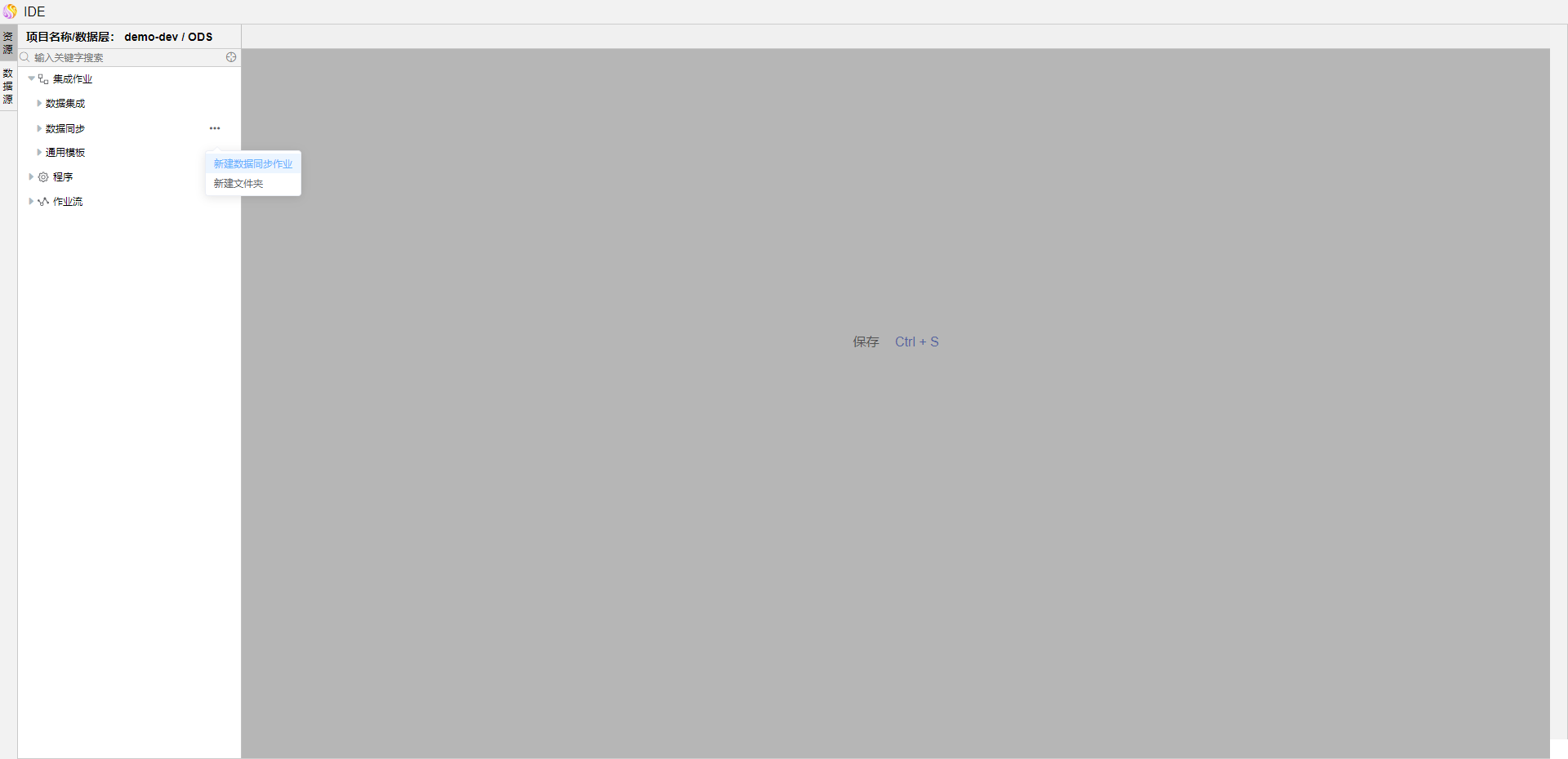
在IDE中依次点击【集成作业】->【数据同步】,点击【数据同步】右侧的...,选择【新建数据同步作业】。
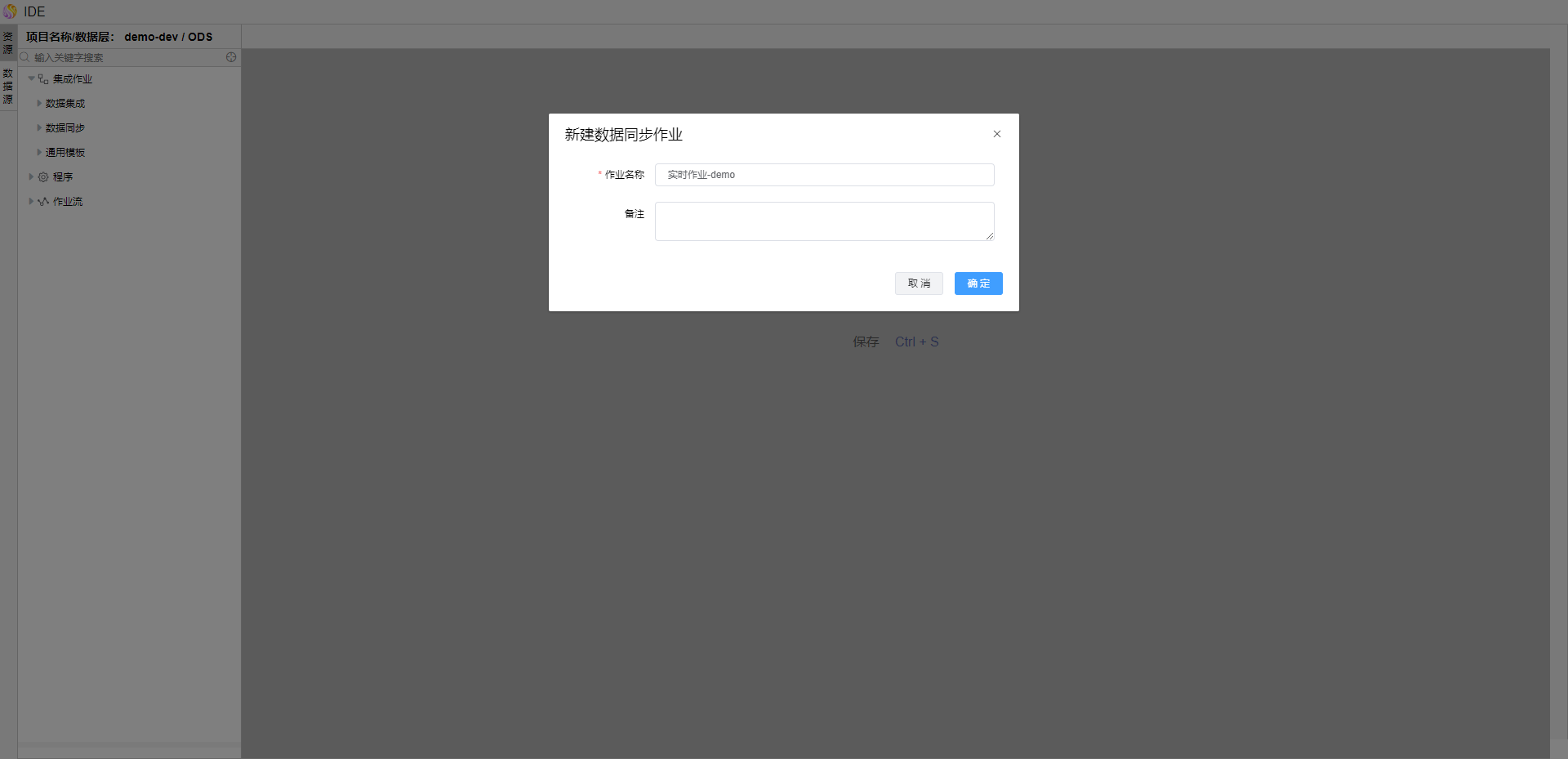
在弹出的【新建数据同步作业】页面,输入作业名称,点击确定按钮。
页面显示实时作业的初始化界面如下图。作业为实时作业的算子,右上侧有【通用配置】、【版本】、【草稿】,右上方有【运行】、【停止】、【保存】、【提交】操作按钮。
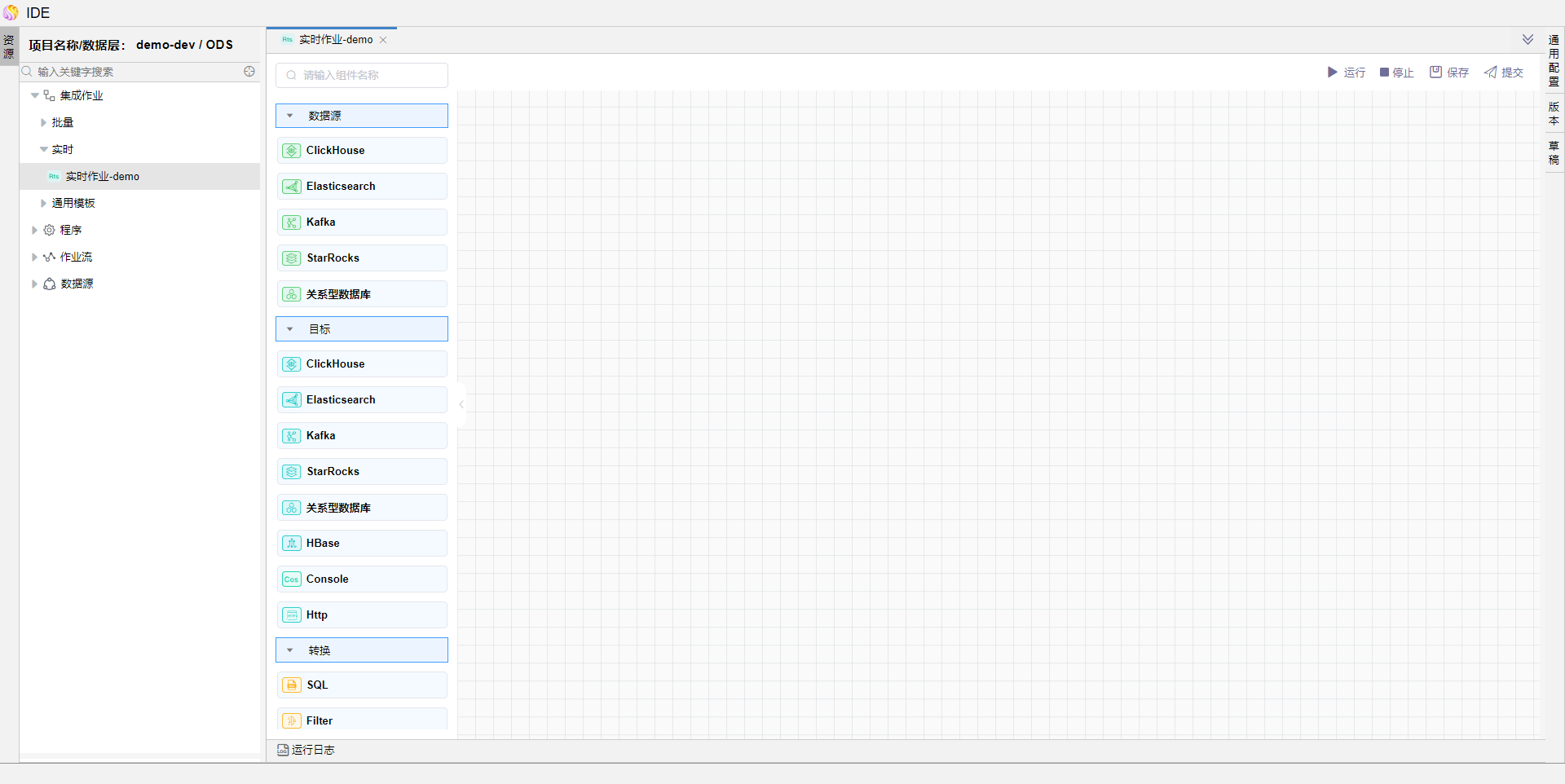
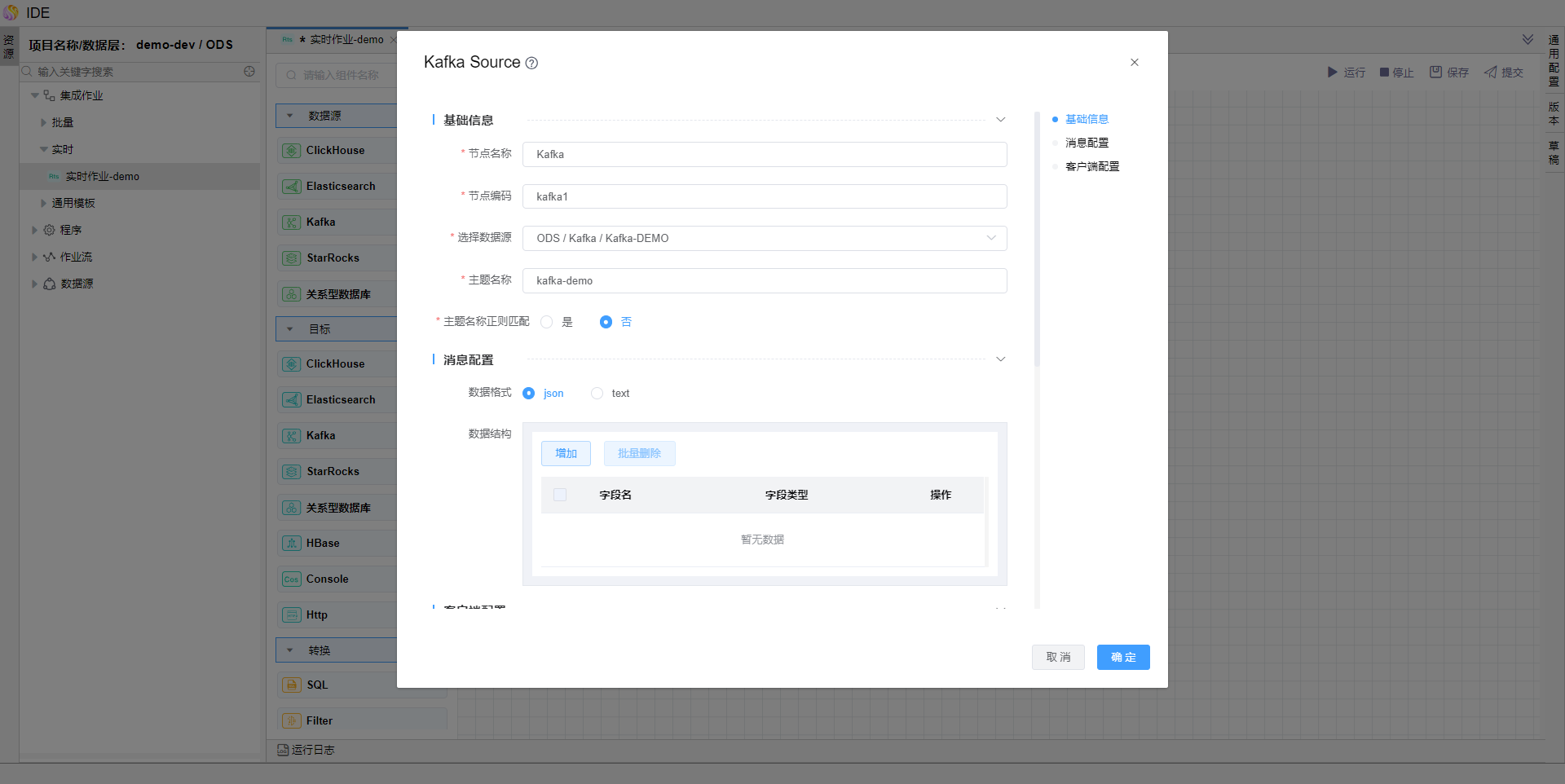
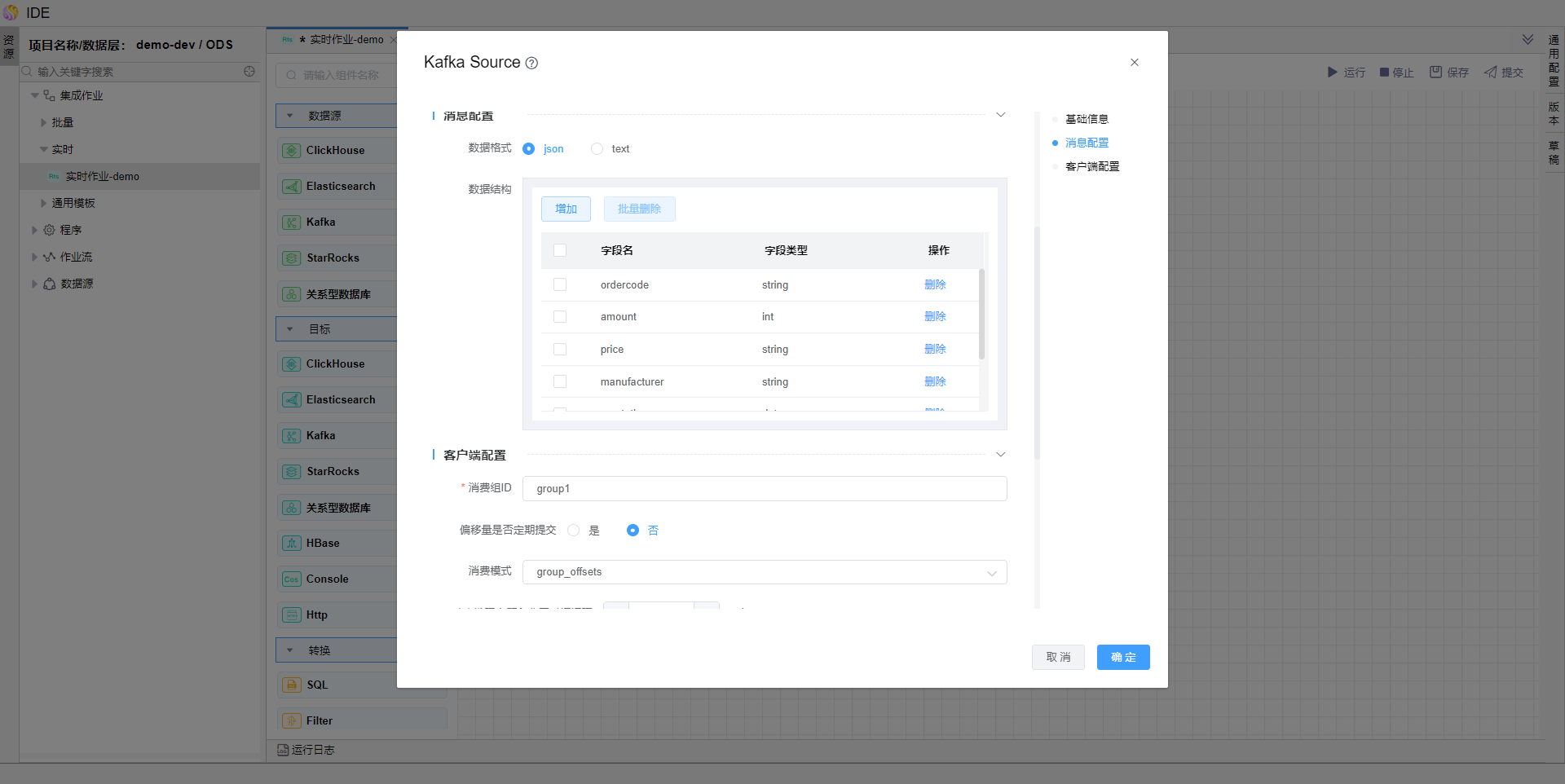
在左侧算子中拖拽【数据源-kafka】、【目标-关系型数据库】算子,并编辑算子信息如图。
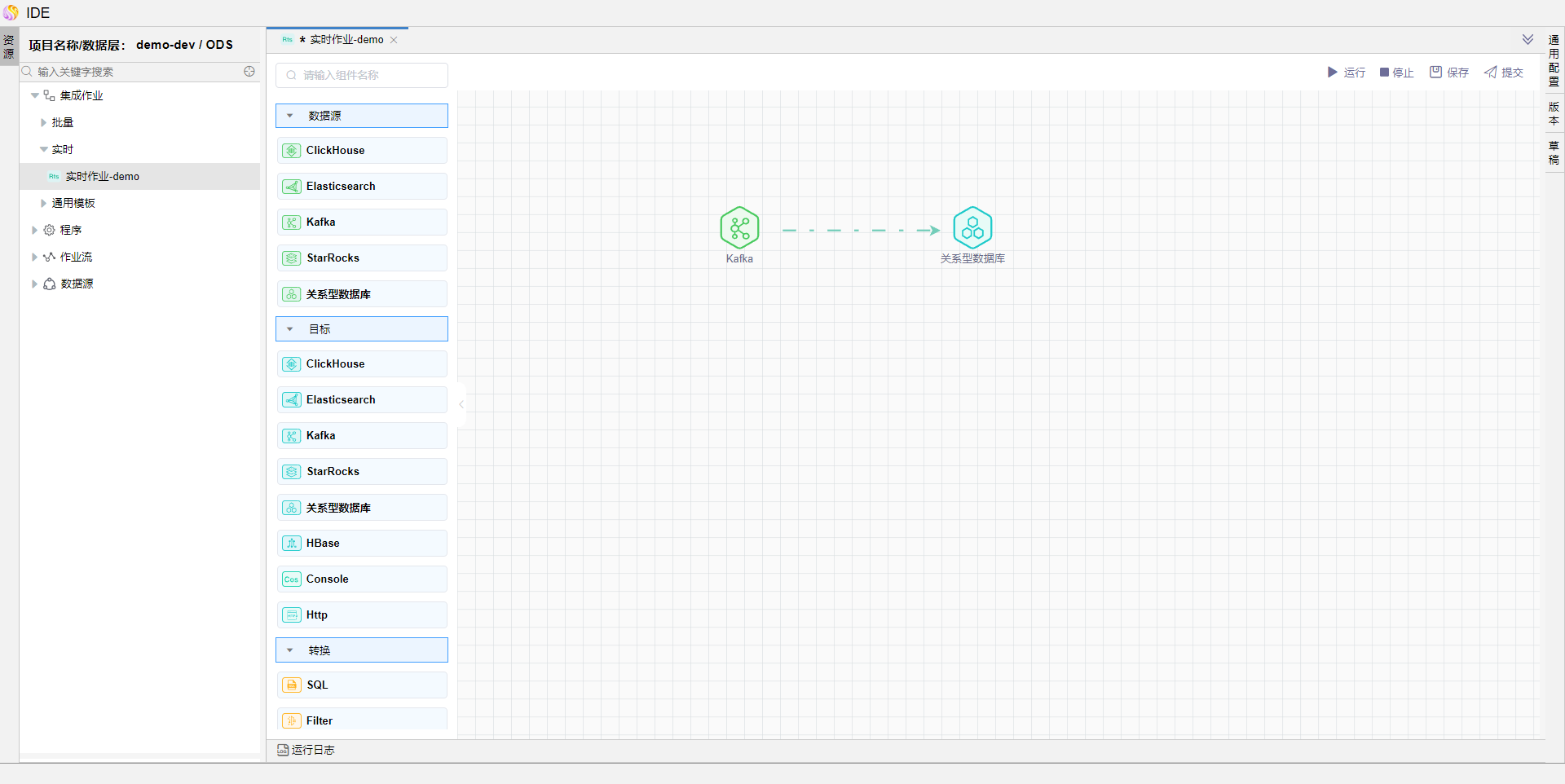
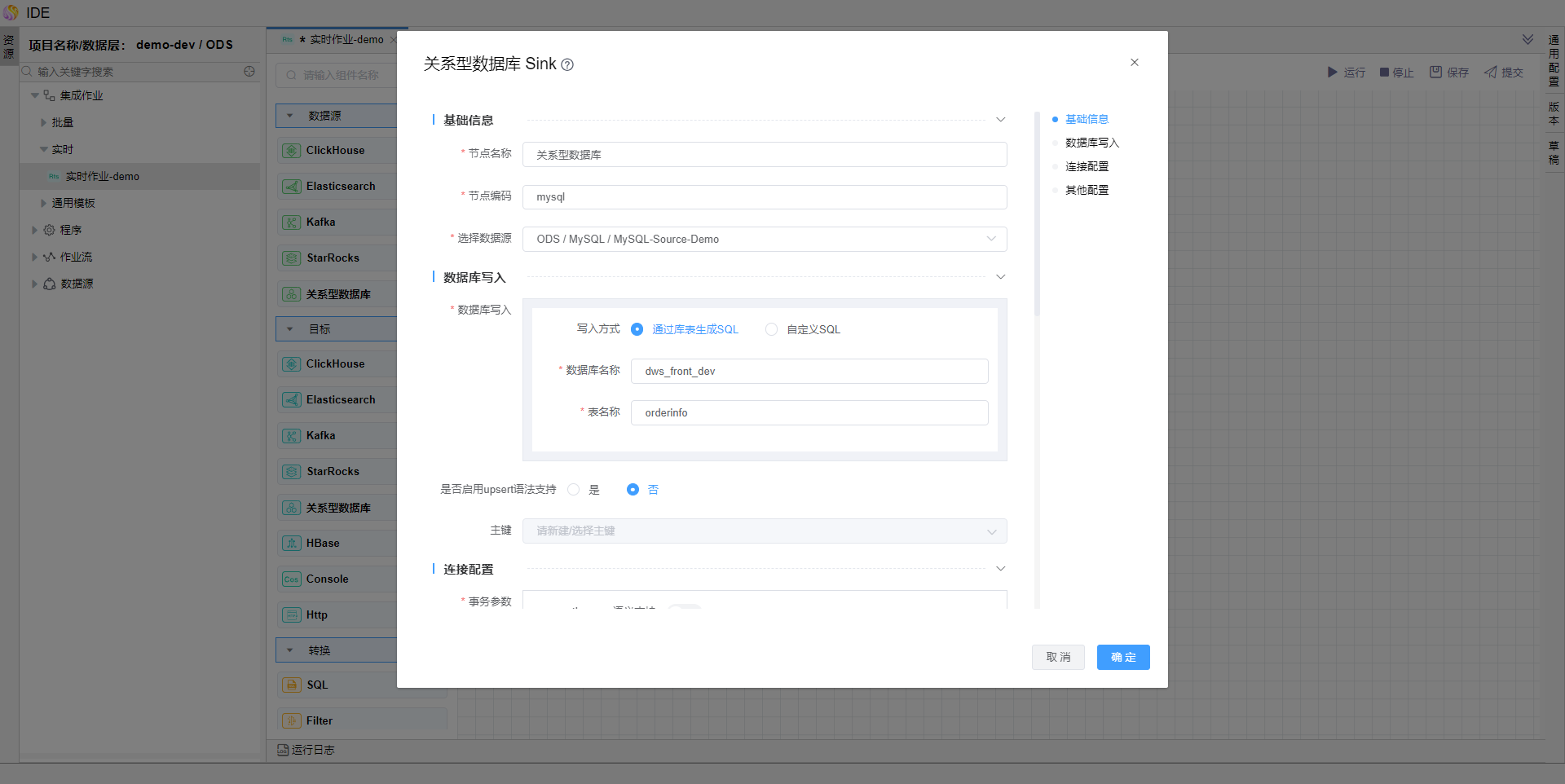
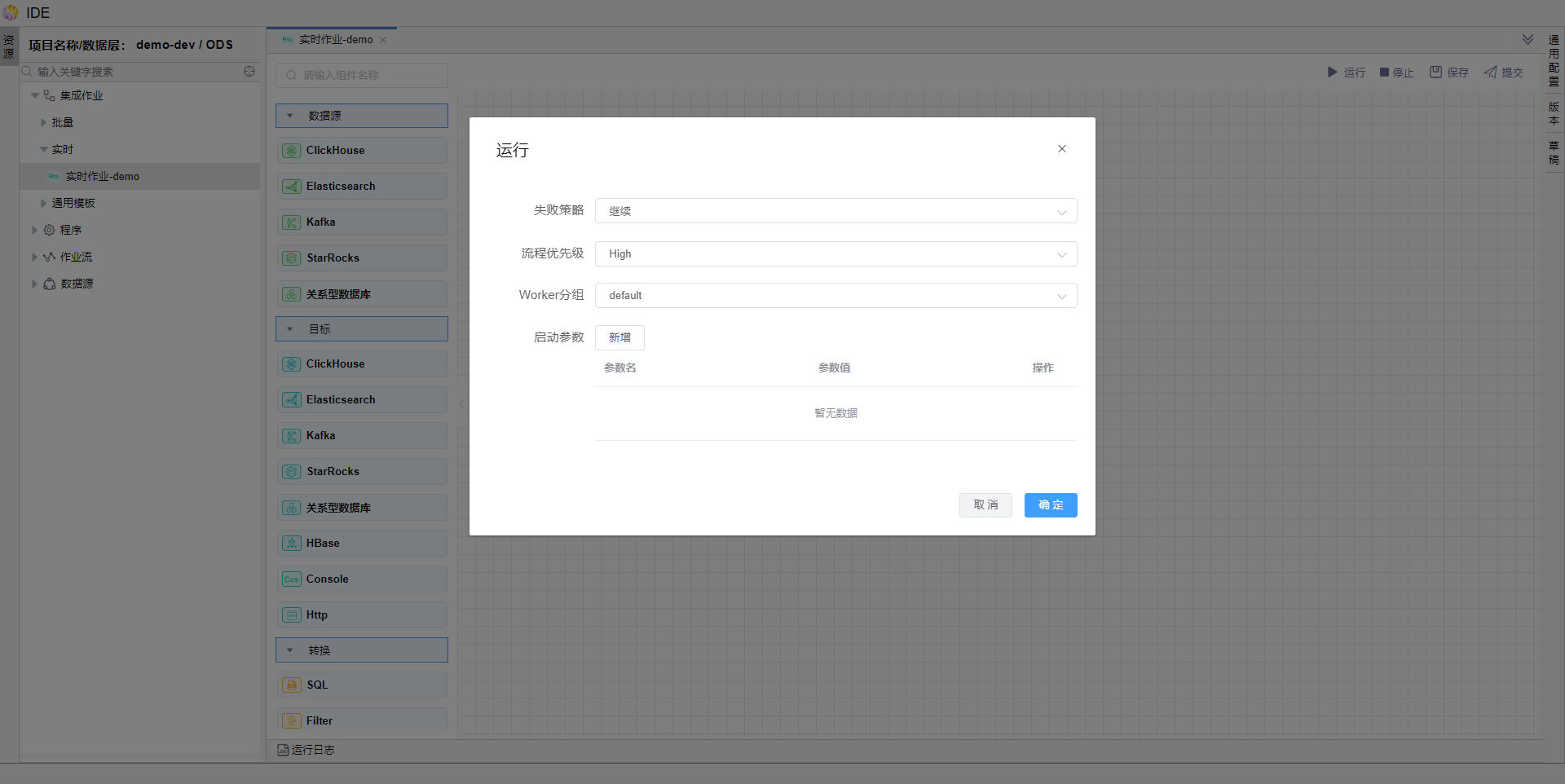
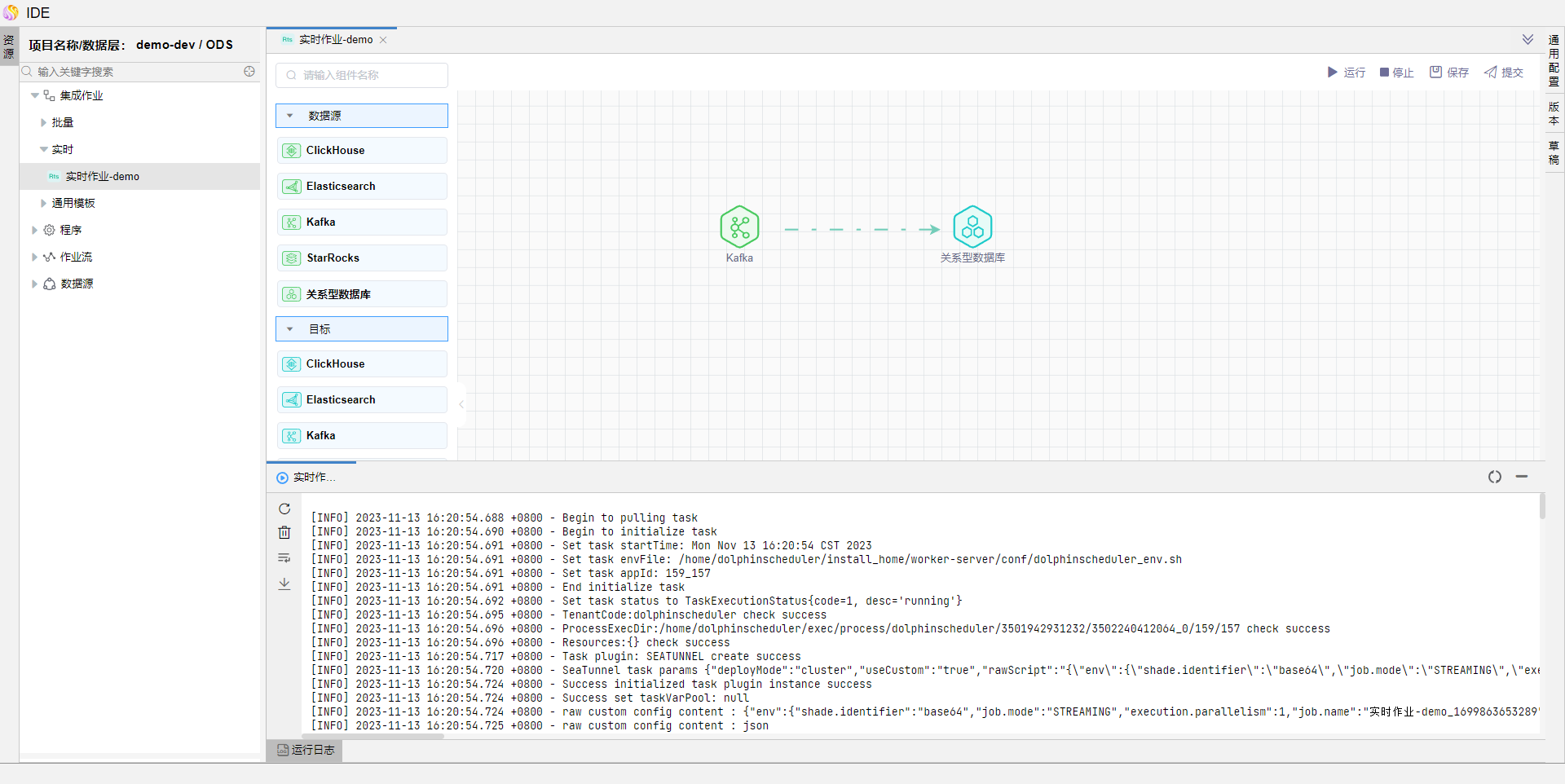
保存模型,点击运行,查看运行结果
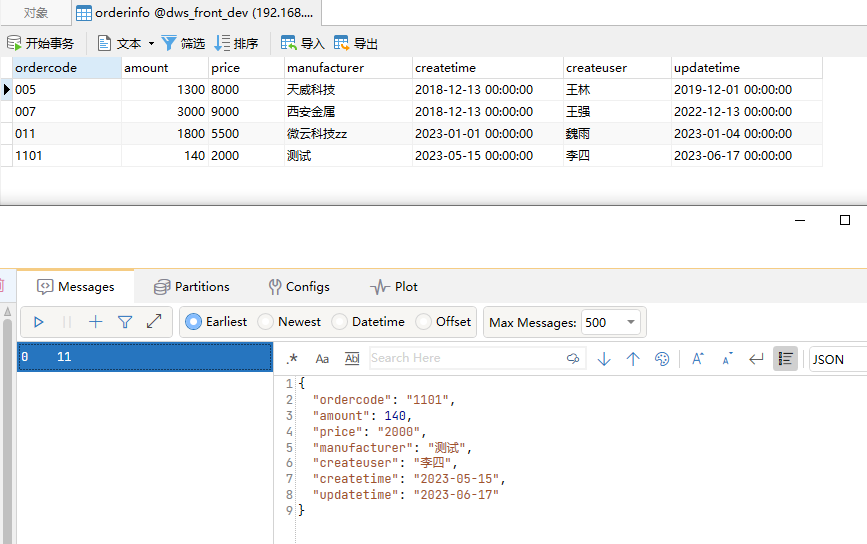
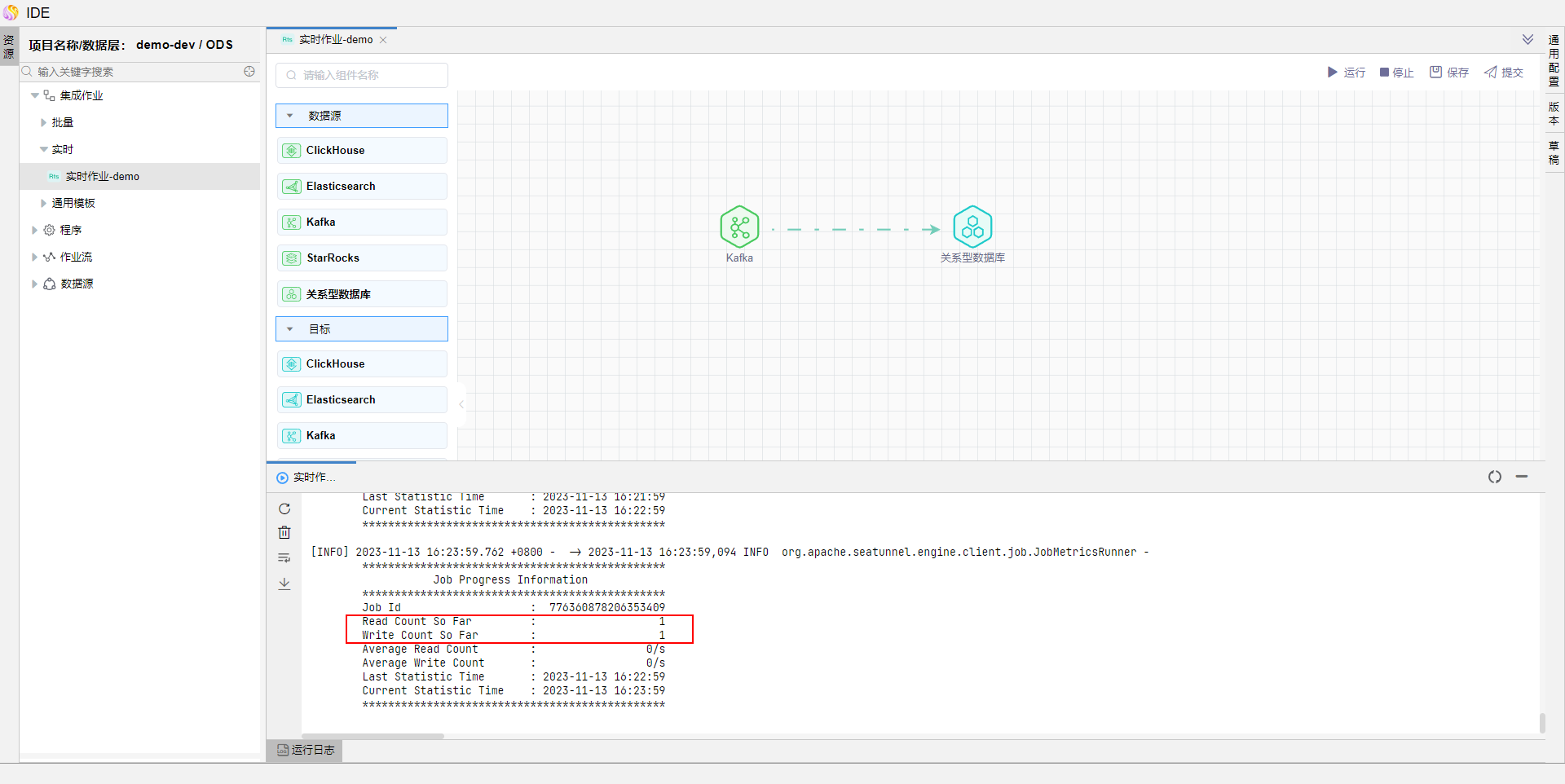
6. 当kafka中有数据时,流处理作业会将数据写入目标关系型数据库中。
若要开发更多类型作业(通用模板、程序等),可参考 开发示例
# 3. 提交运行
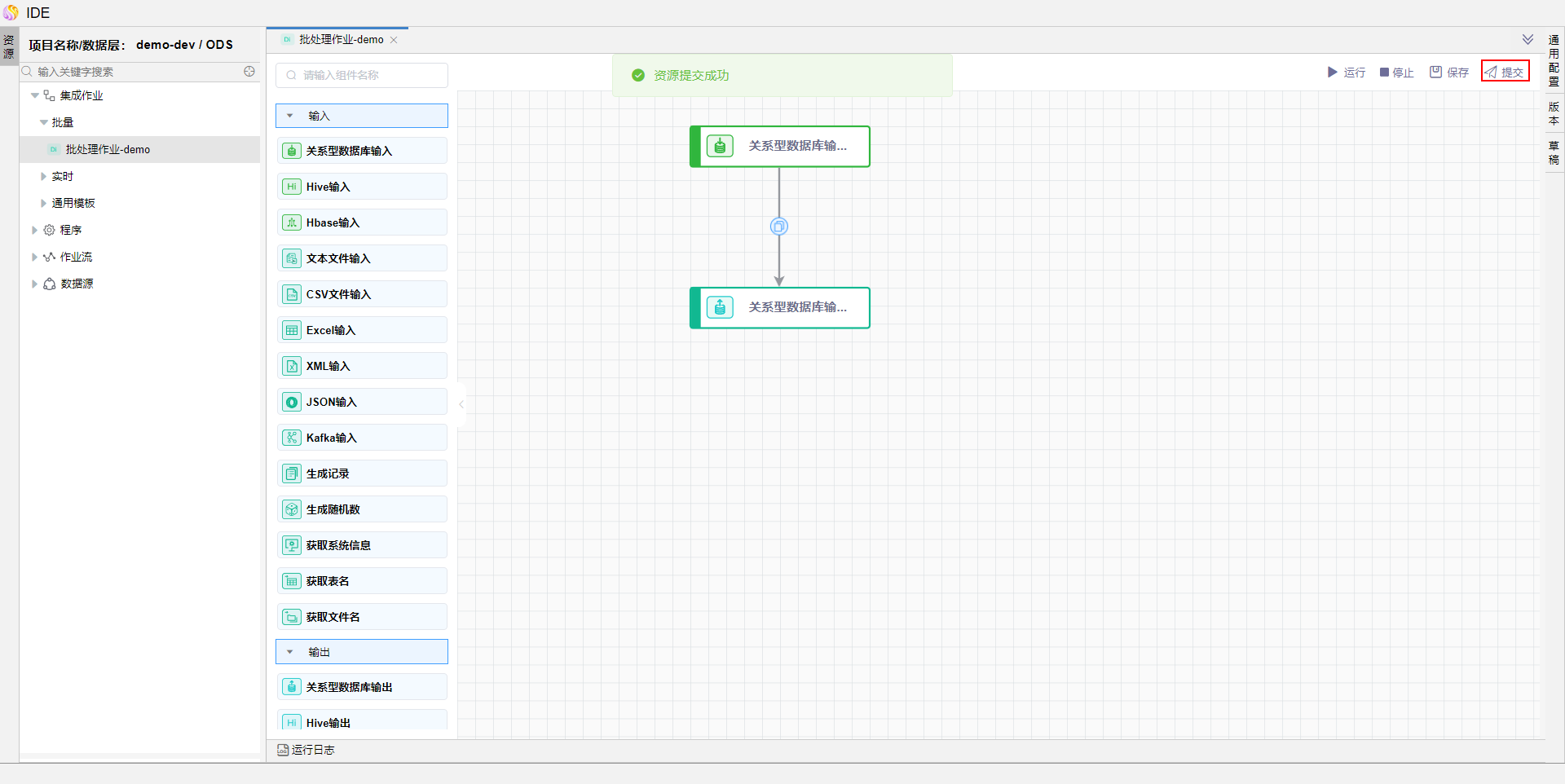
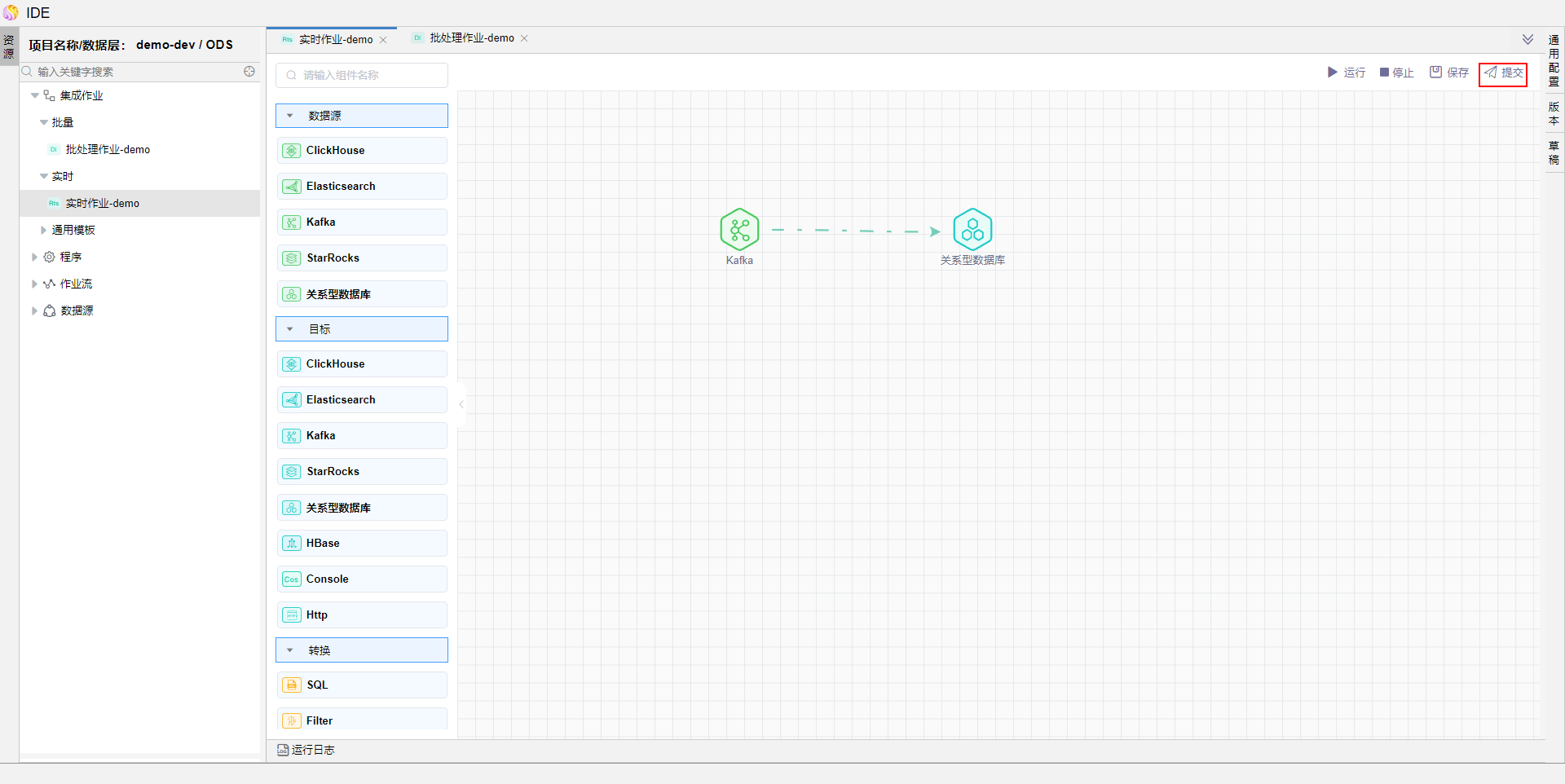
分别将上述批处理作业和流处理作业提交
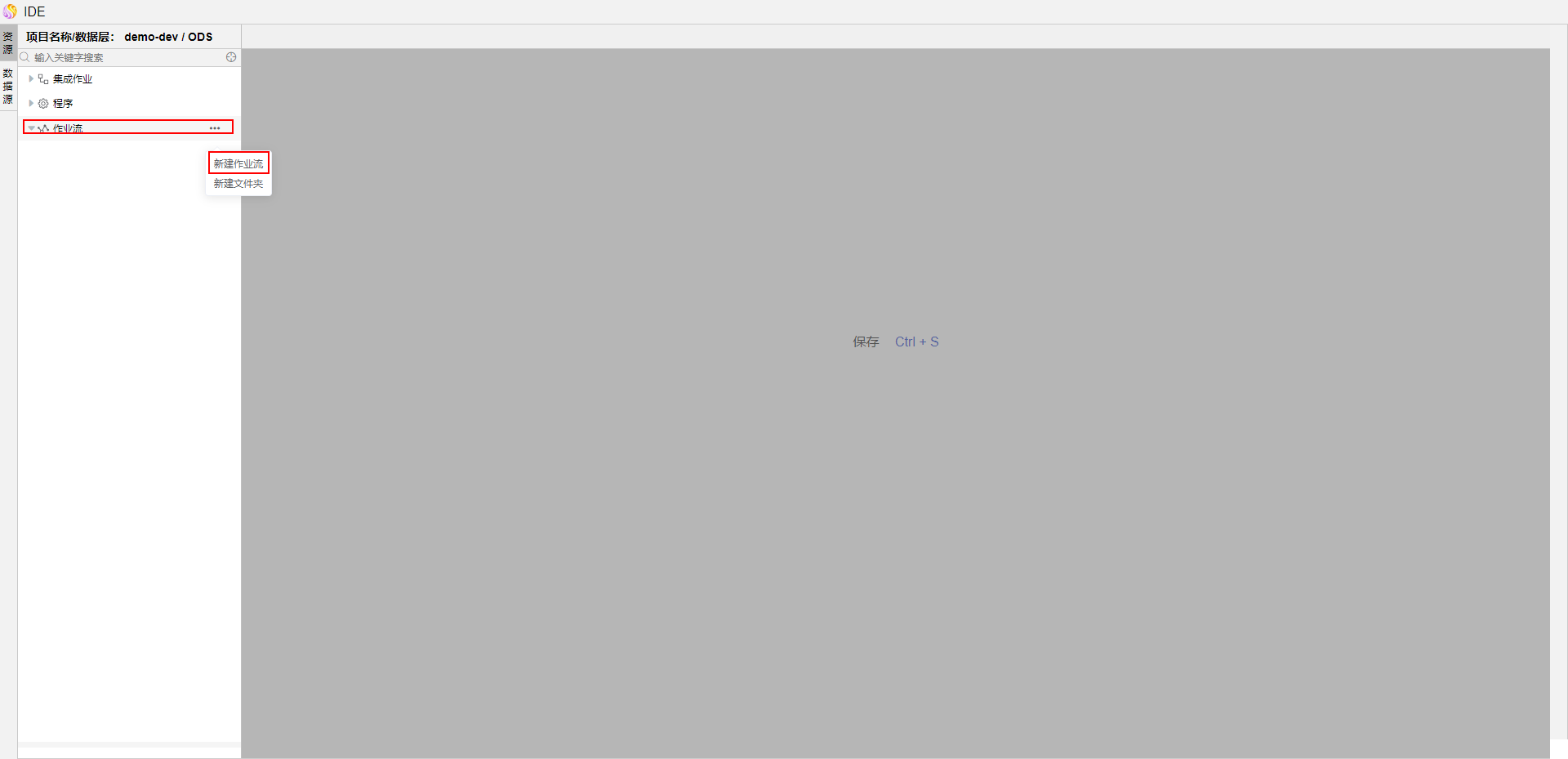
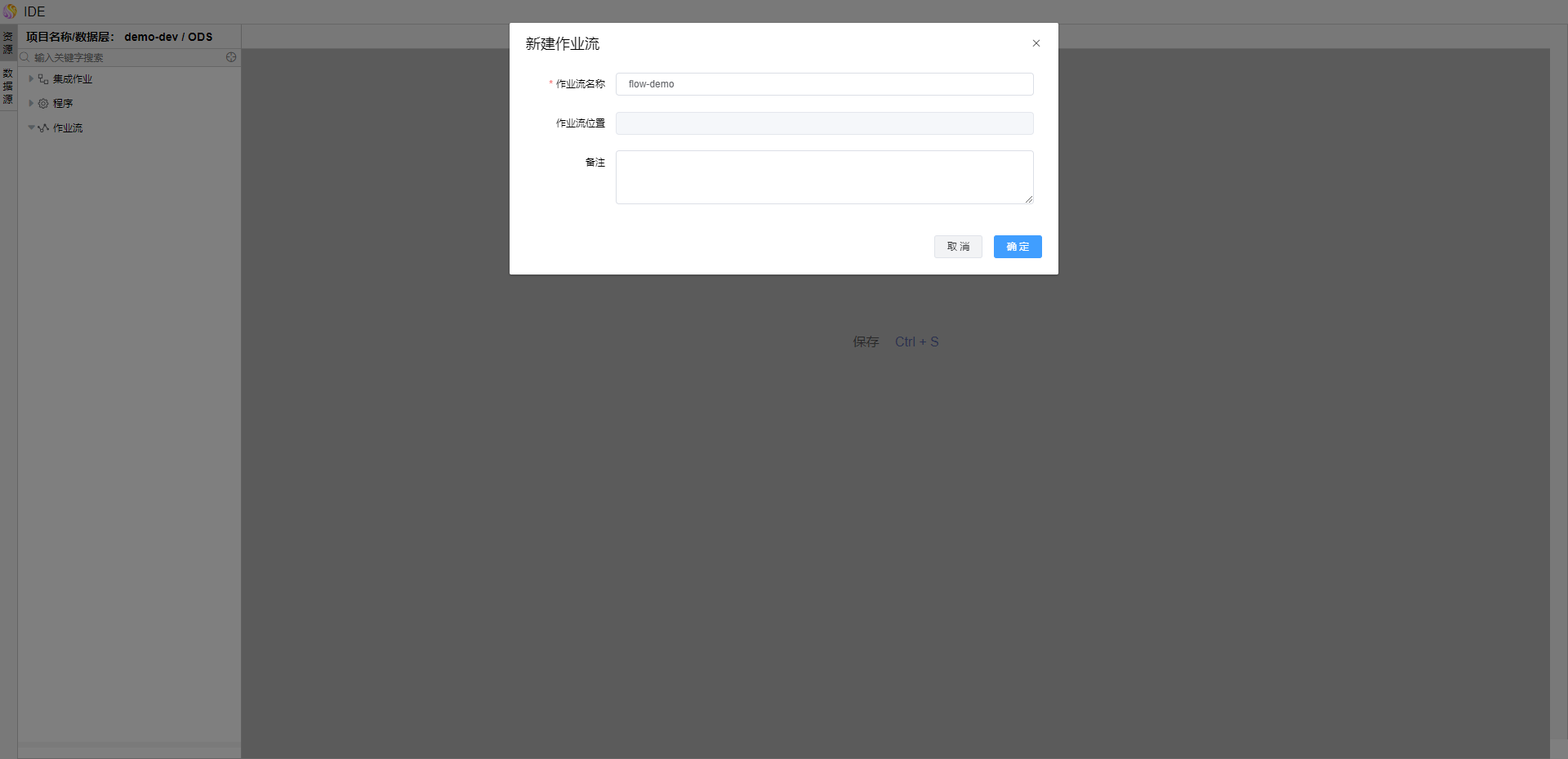
在【作业流】节点点击...,点击【新建作业流】,输入作业流名称并保存。
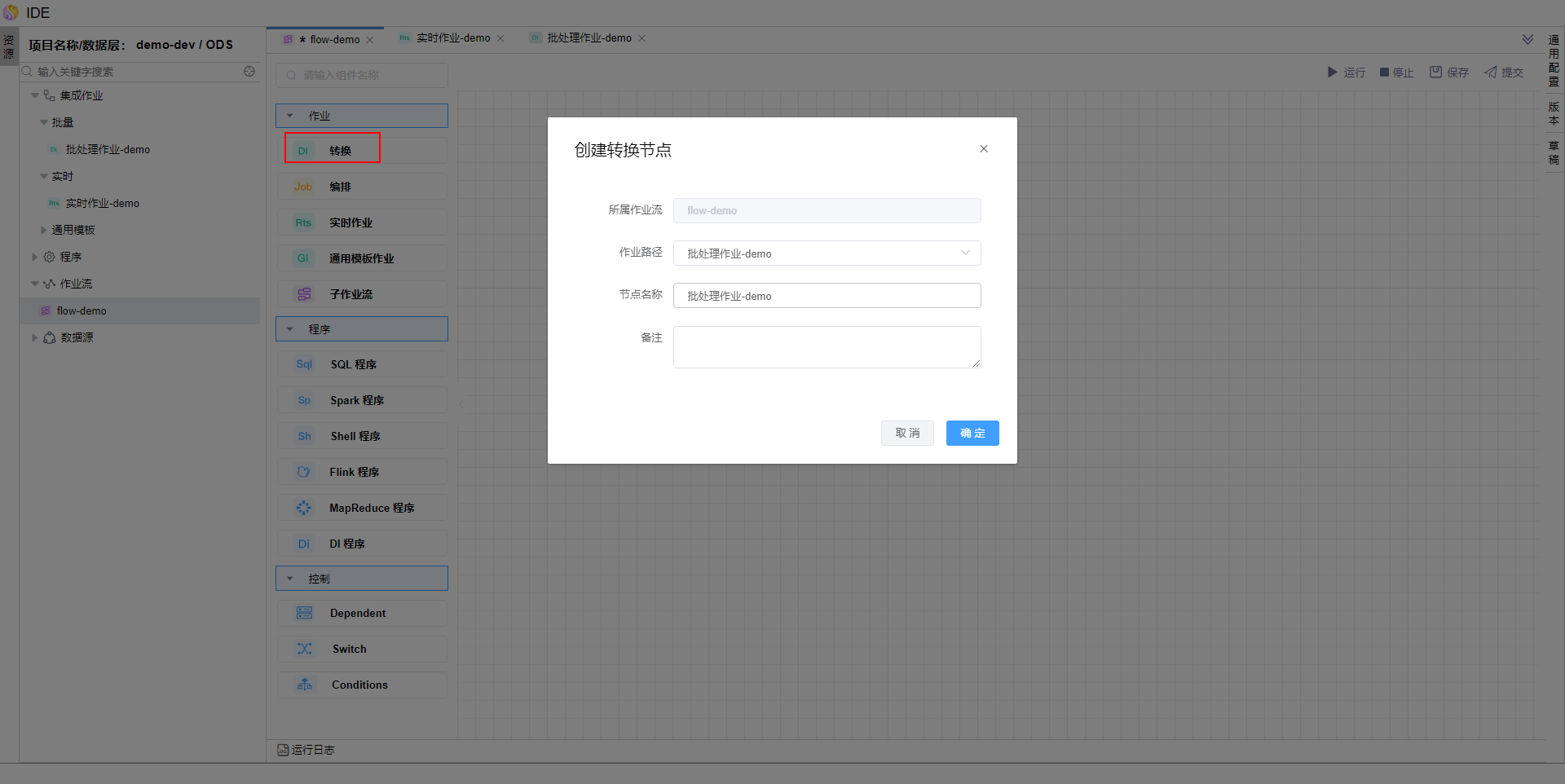
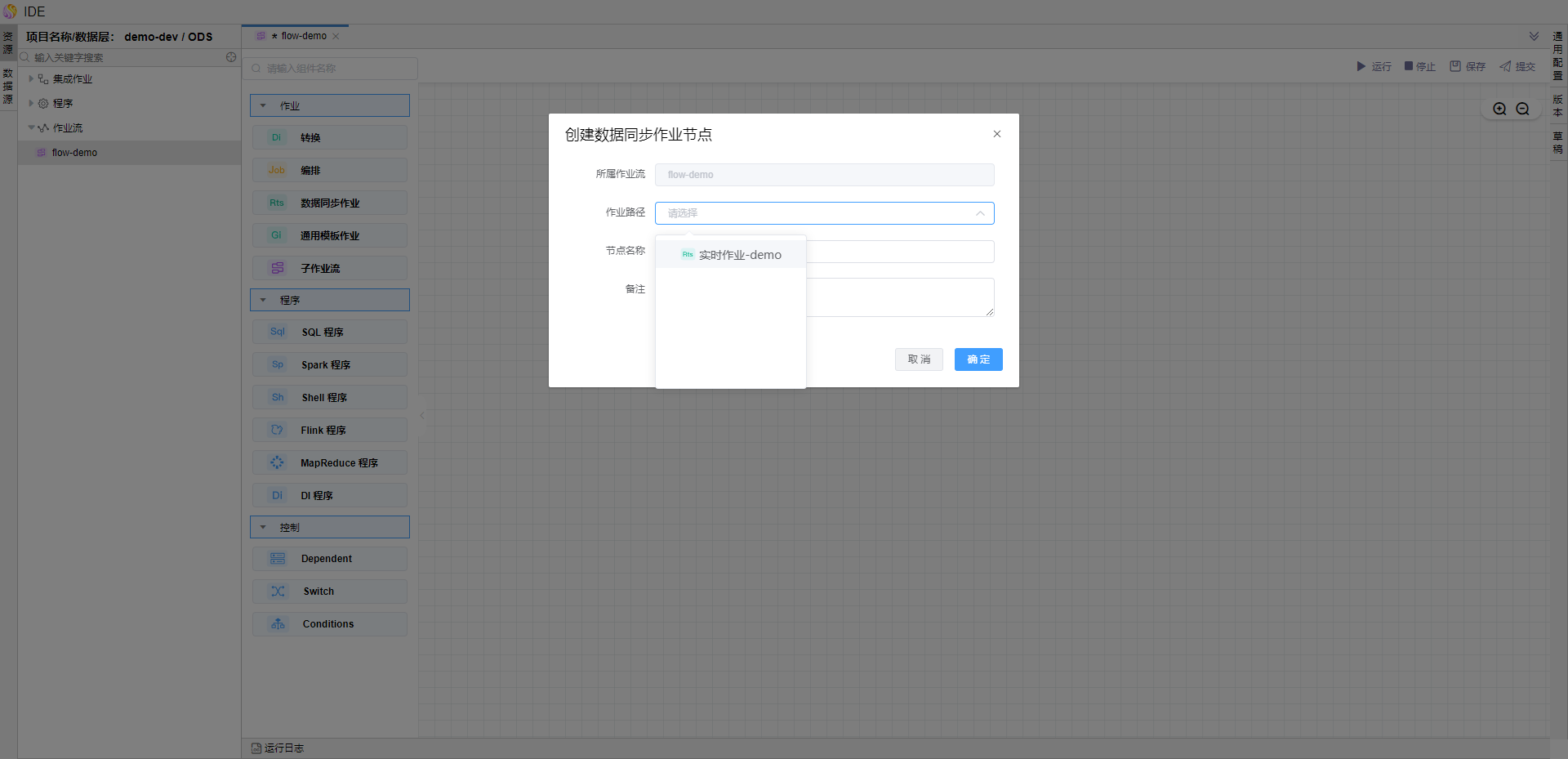
在作业流画布中,依次拖拽【转换】【数据同步作业】算子,并选择之前提交的批处理作业和流处理作业。
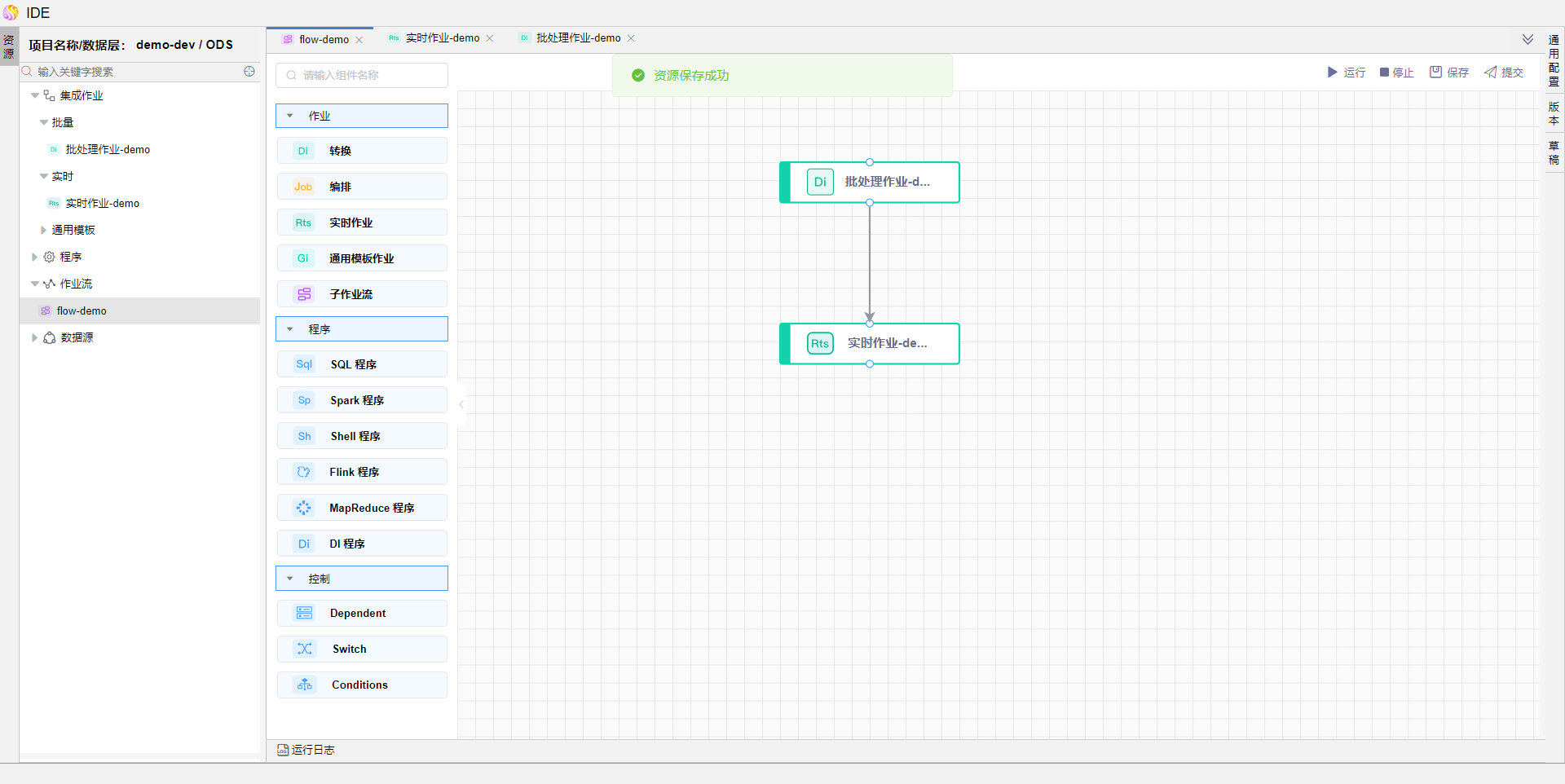
编辑作业流的【通用配置】,输入全局参数date1,点击【确定】按钮保存通用配置。
该全局参数是批处理作业中的命名参数的传参
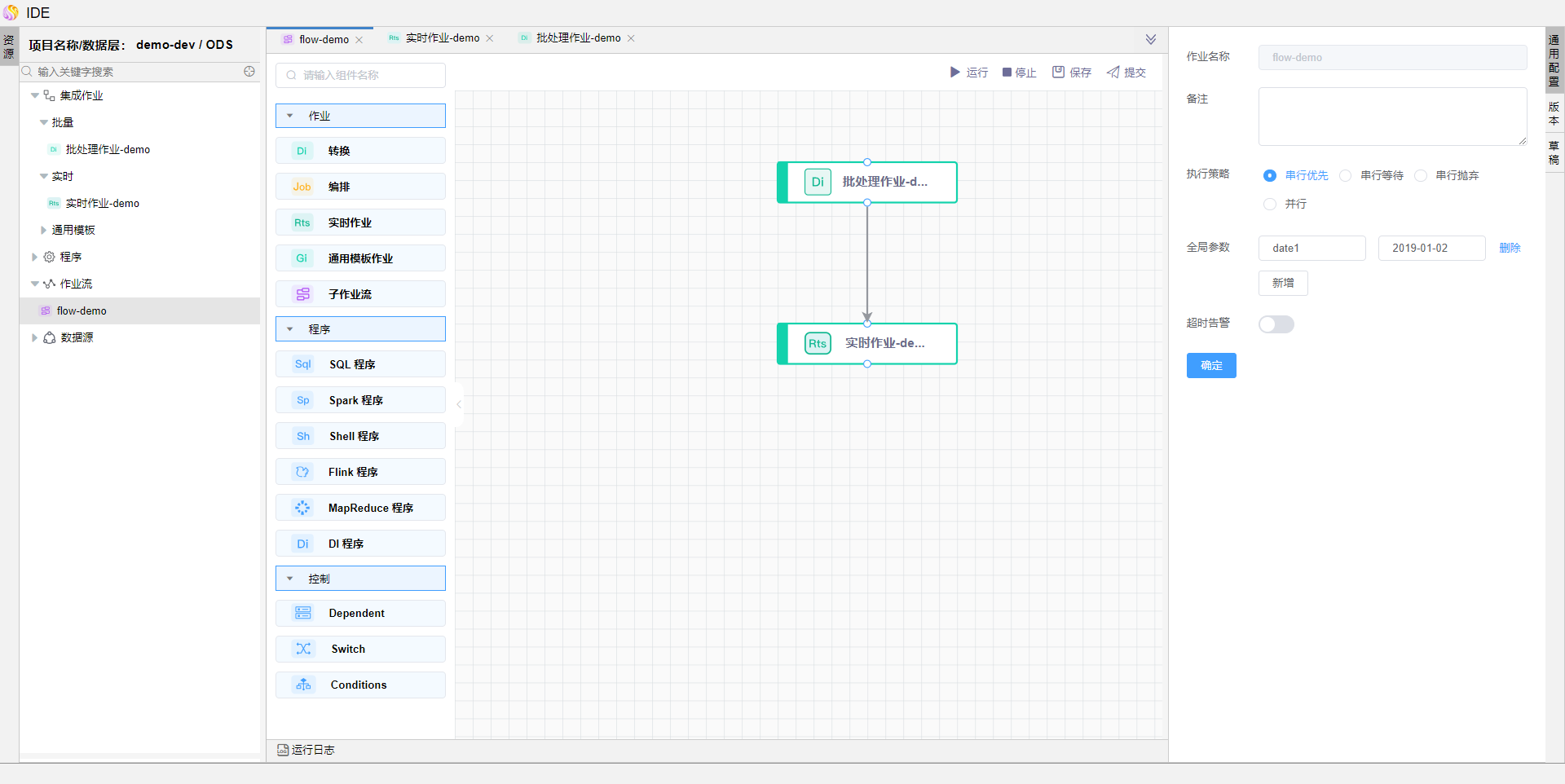
提交作业流

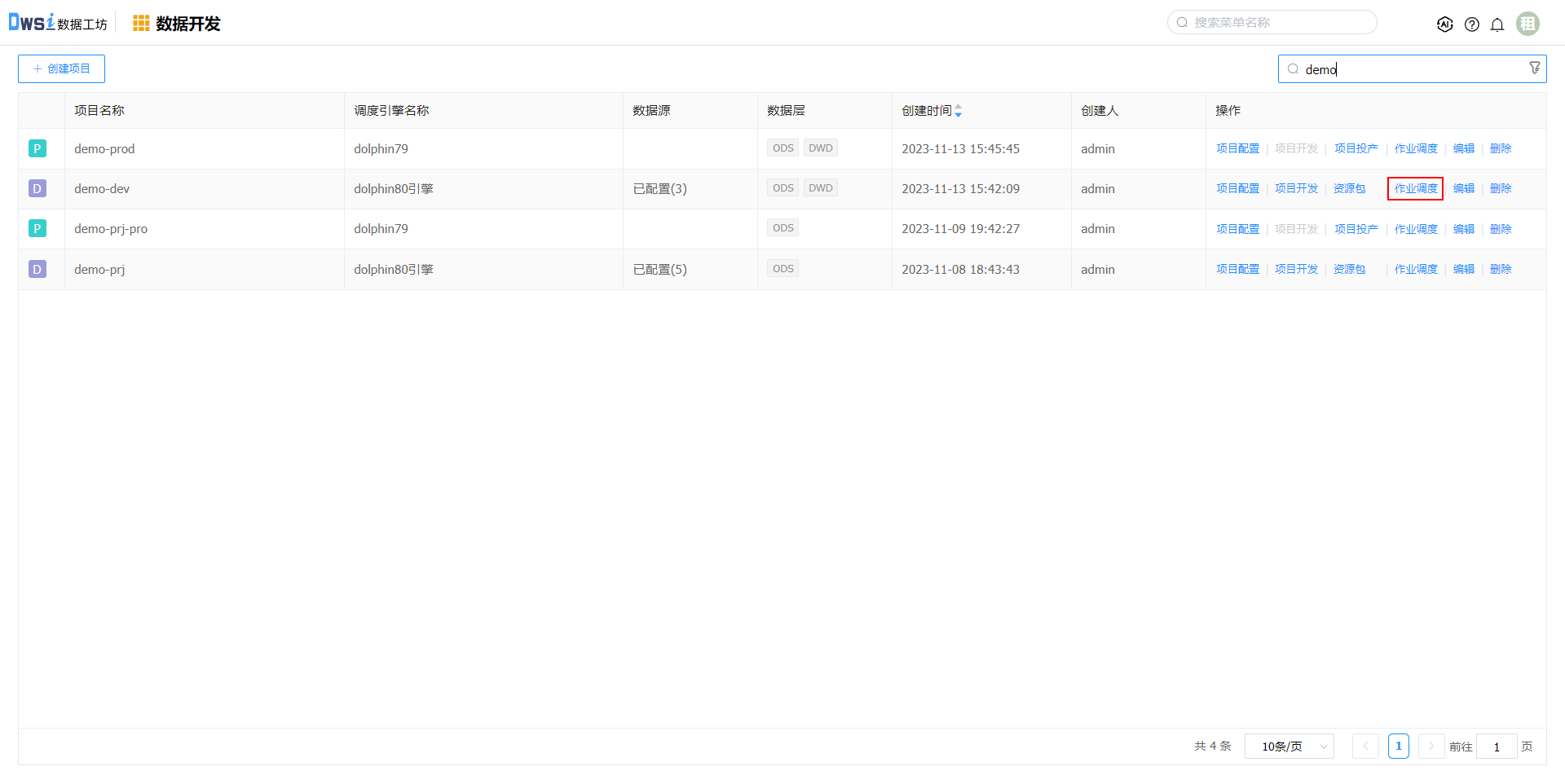
返回【数据开发】,选择对应的项目,点击”作业调度“操作,跳转到该项目使用的引擎已提交的作业流页面。
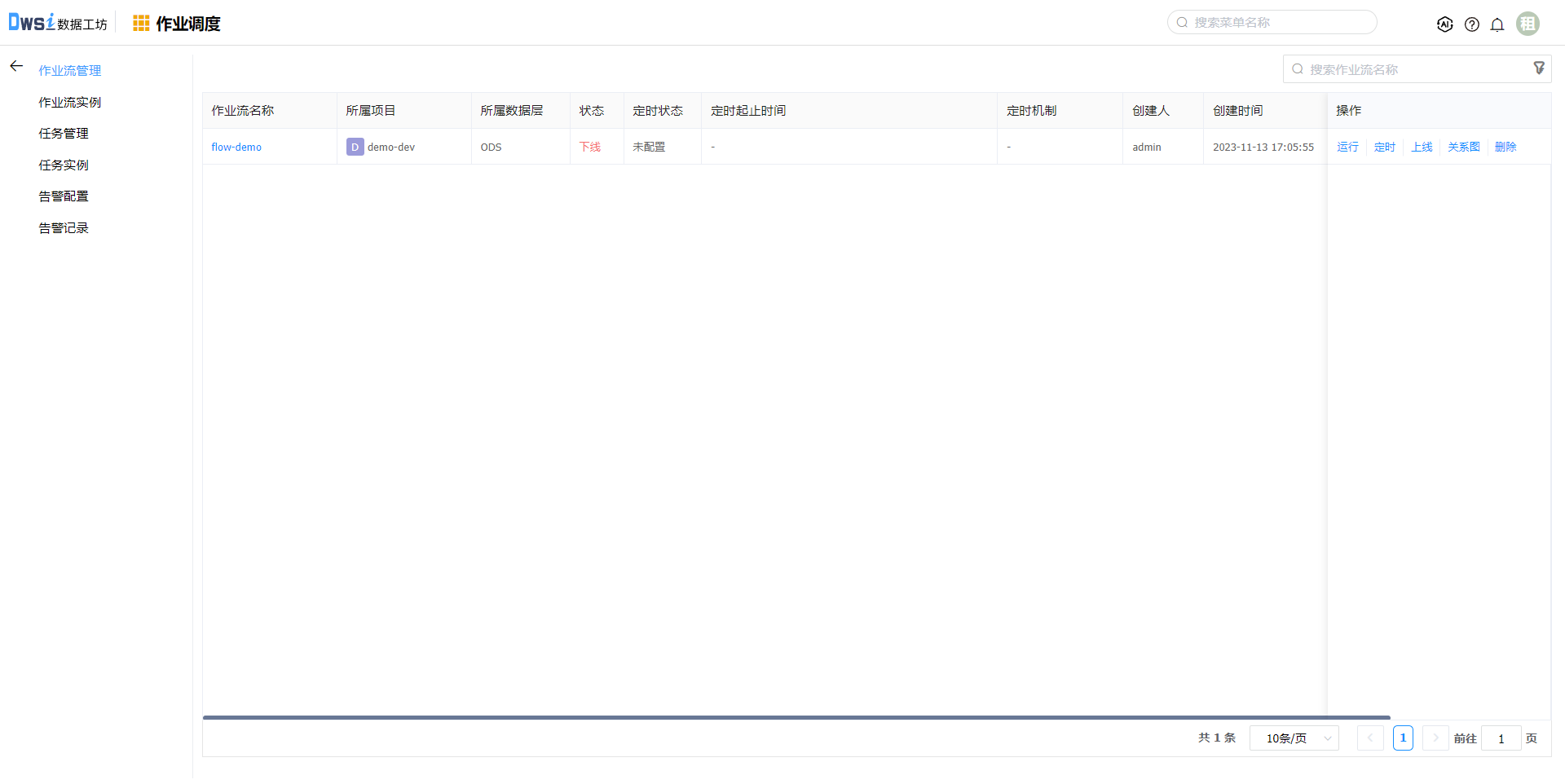
点击上线操作,作业流状态变更为“上线”
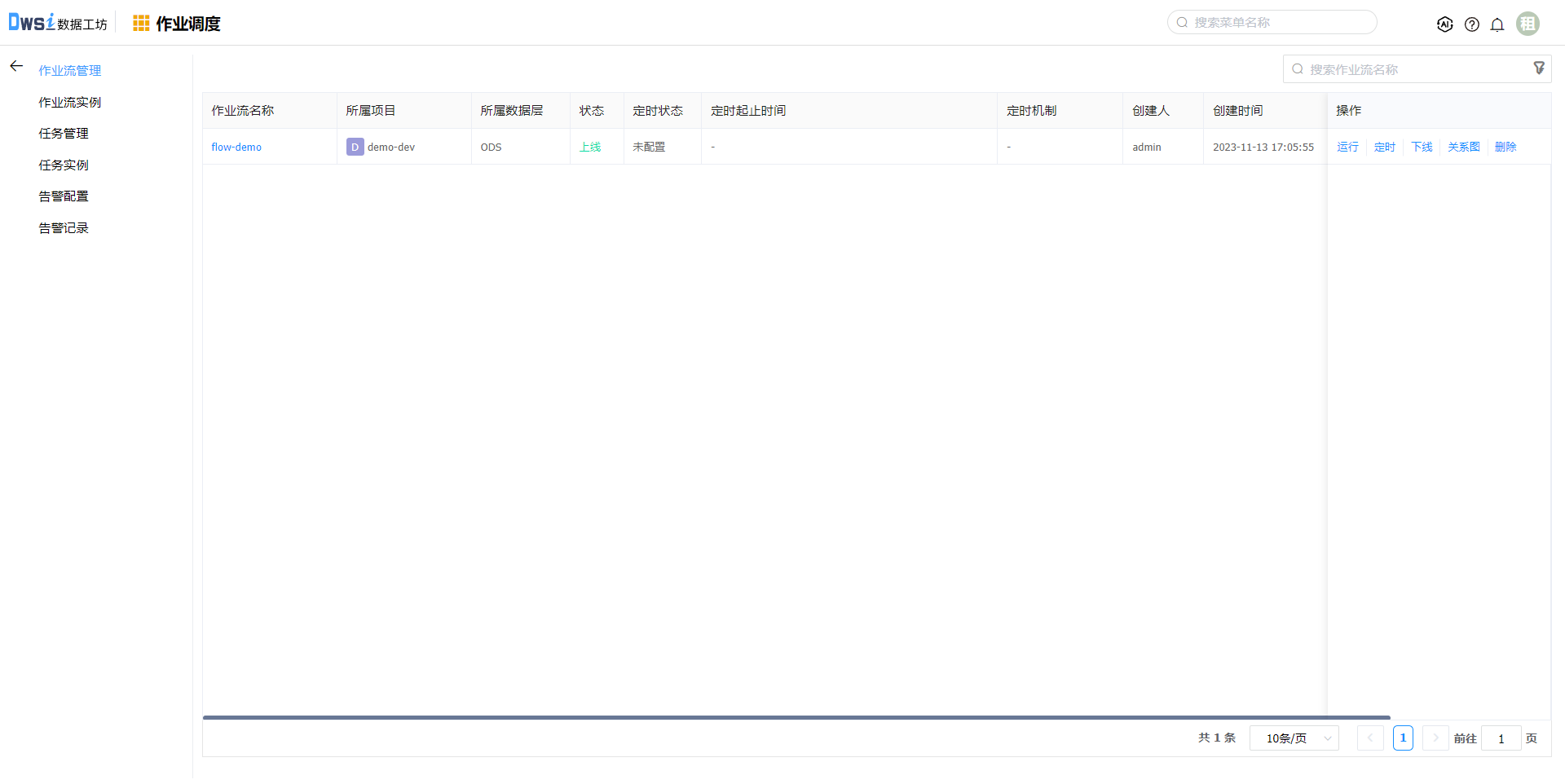
点击运行按钮,可运行该作业流。
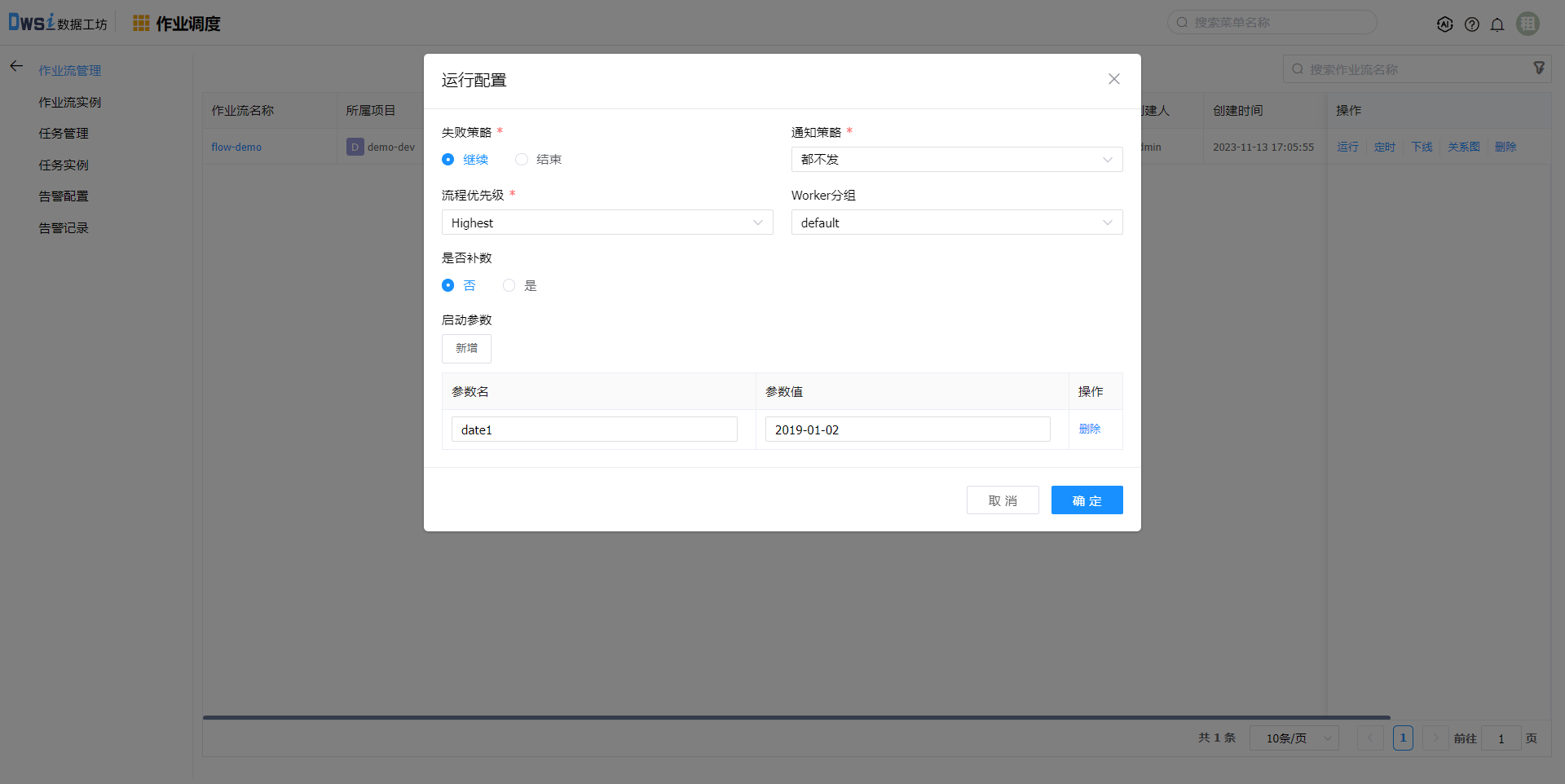
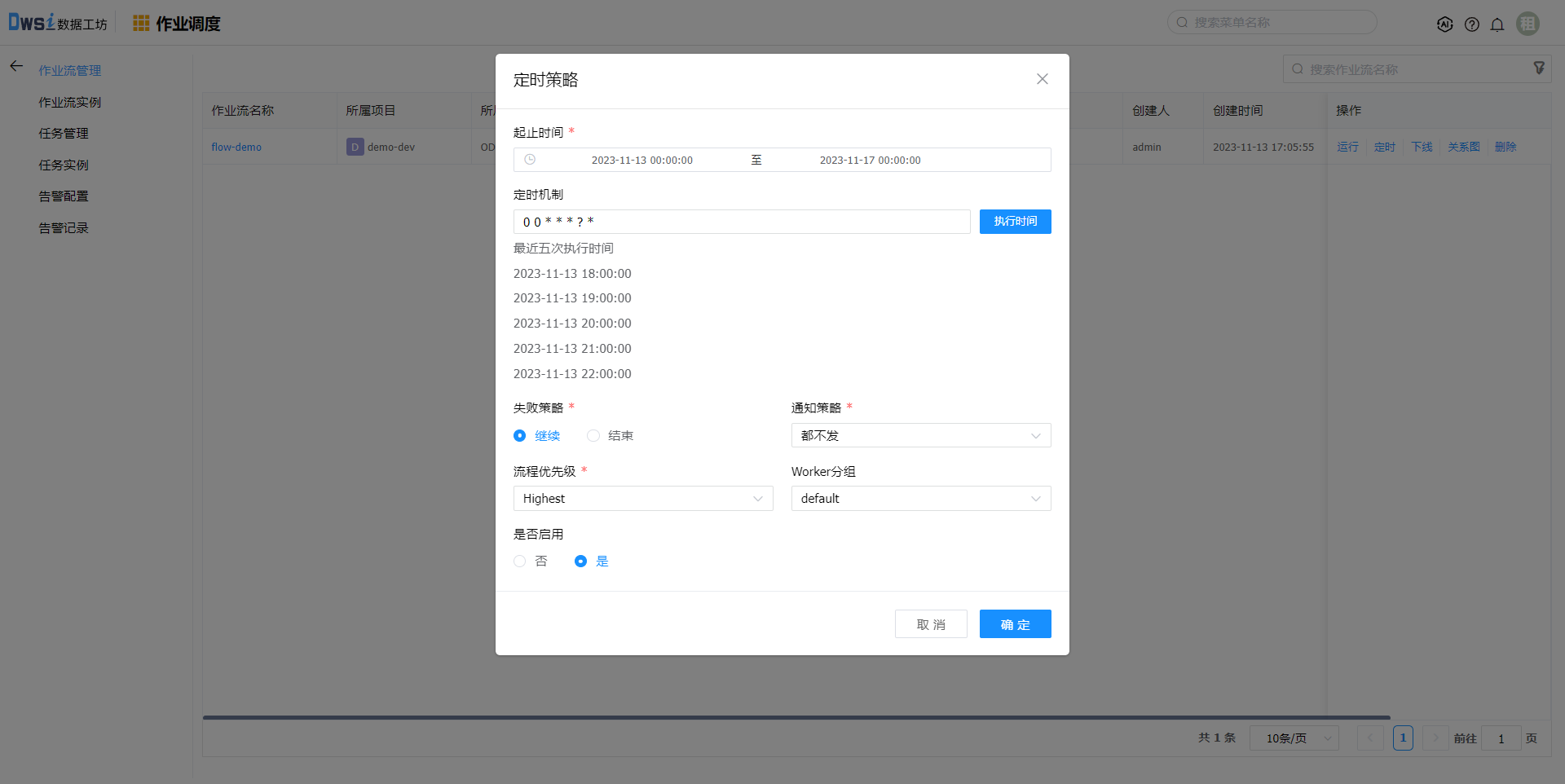
点击定时可配置定时运行策略,启用后生效。