
# 通用模板作业
本章节将详细讲述基于 Primeton DI 引擎的数据同步通用模板的使用。
全量同步
增量同步
数据库同步:可以实现将数据库单表、多表、整库的迁移,将全部数据一次性从源表迁移到目标表。
- 单表:只选择一张表名,可快速实现两个表之间的数据批量迁移。
- 多表:选择多张表名,可快速实现多个表之间的数据批量迁移。
- 整库:全选表名。整库同步是帮助用户提升数据同步效率的工具,通过整库同步可快速实现两个库之间的数据批量迁移,节省任务配置工作,快速提升数据迁移效率。
# 关系型数据库同步(全量)
数据库同步一共有四步:
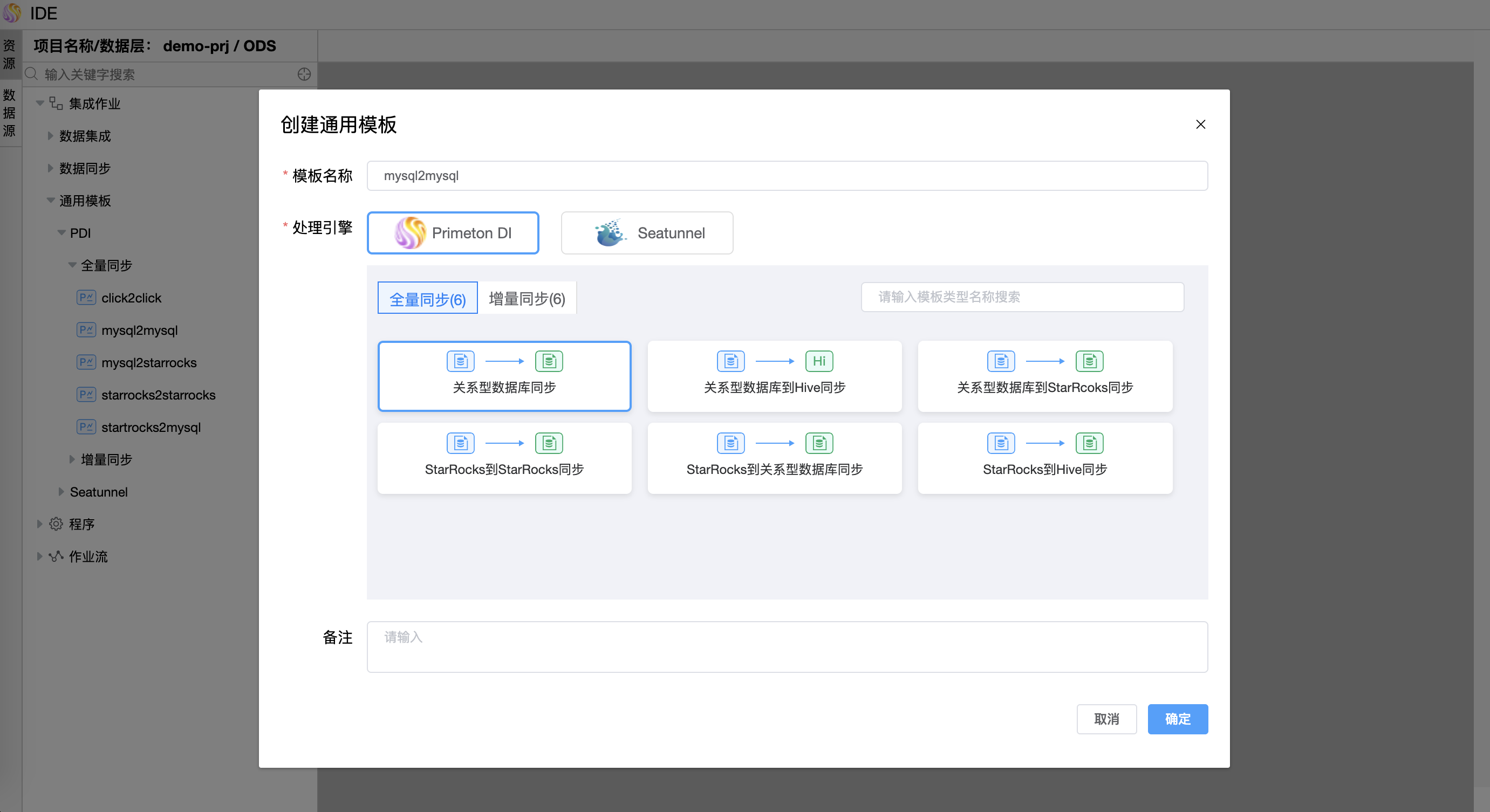
- 第一步:创建通用模板作业,选择处理引擎 "Primeton DI",选择"全量同步",选择"关系型数据库同步"模板。
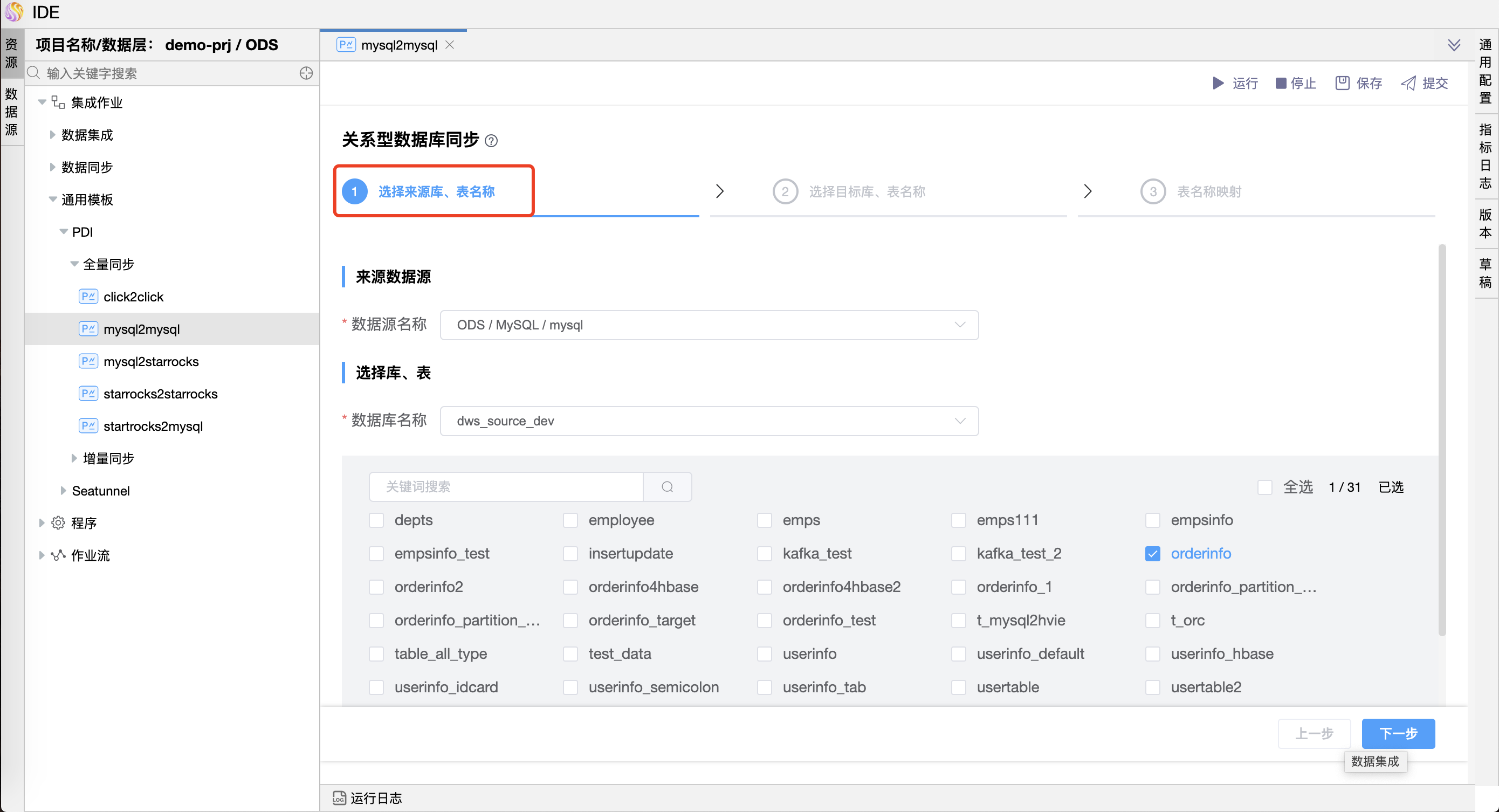
- 第二步:选择来源库、表名称。
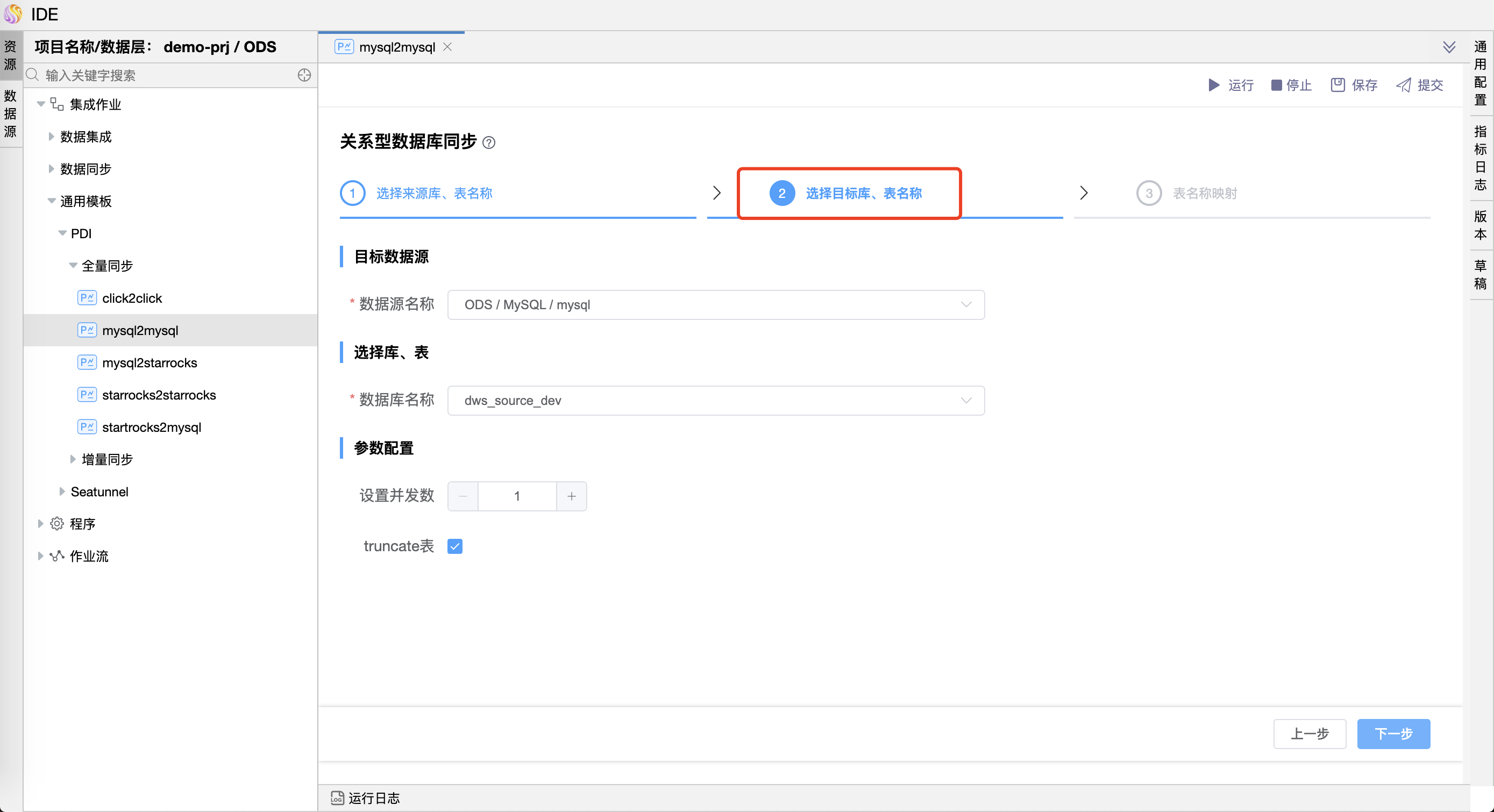
- 第三步:选择目标库、表名称。
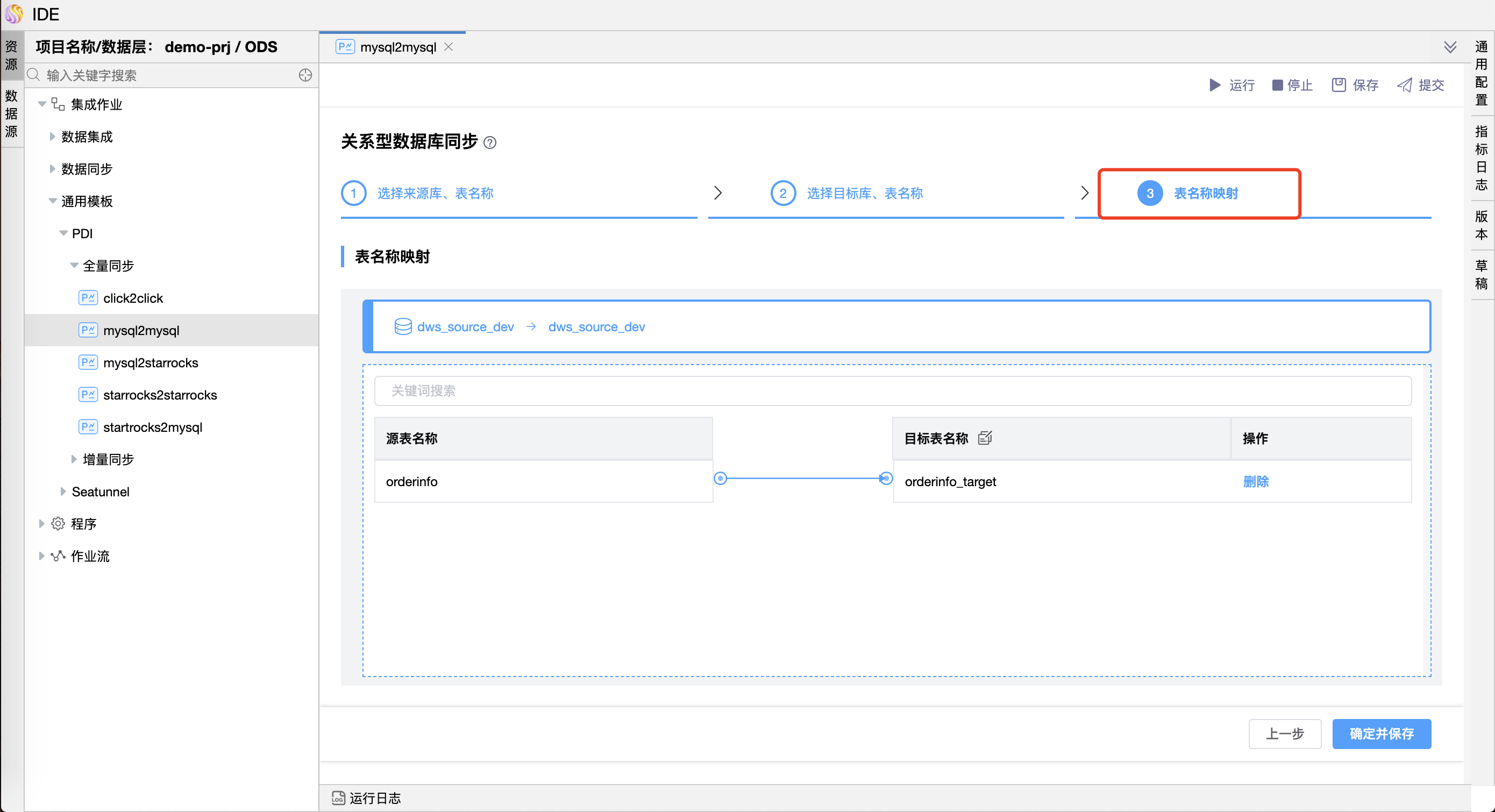
- 第四步:来源库表名称与目标库表名称的映射。
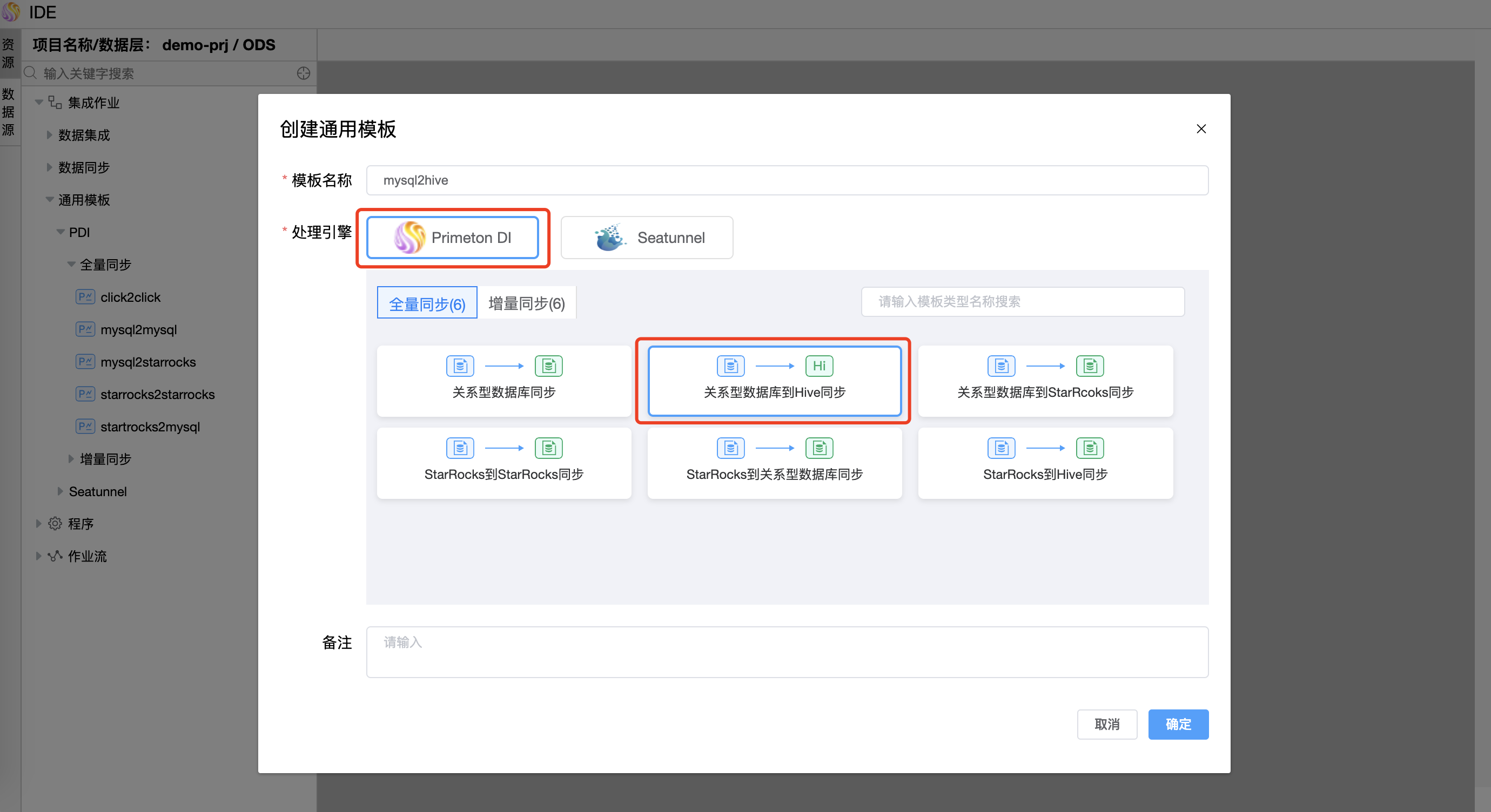
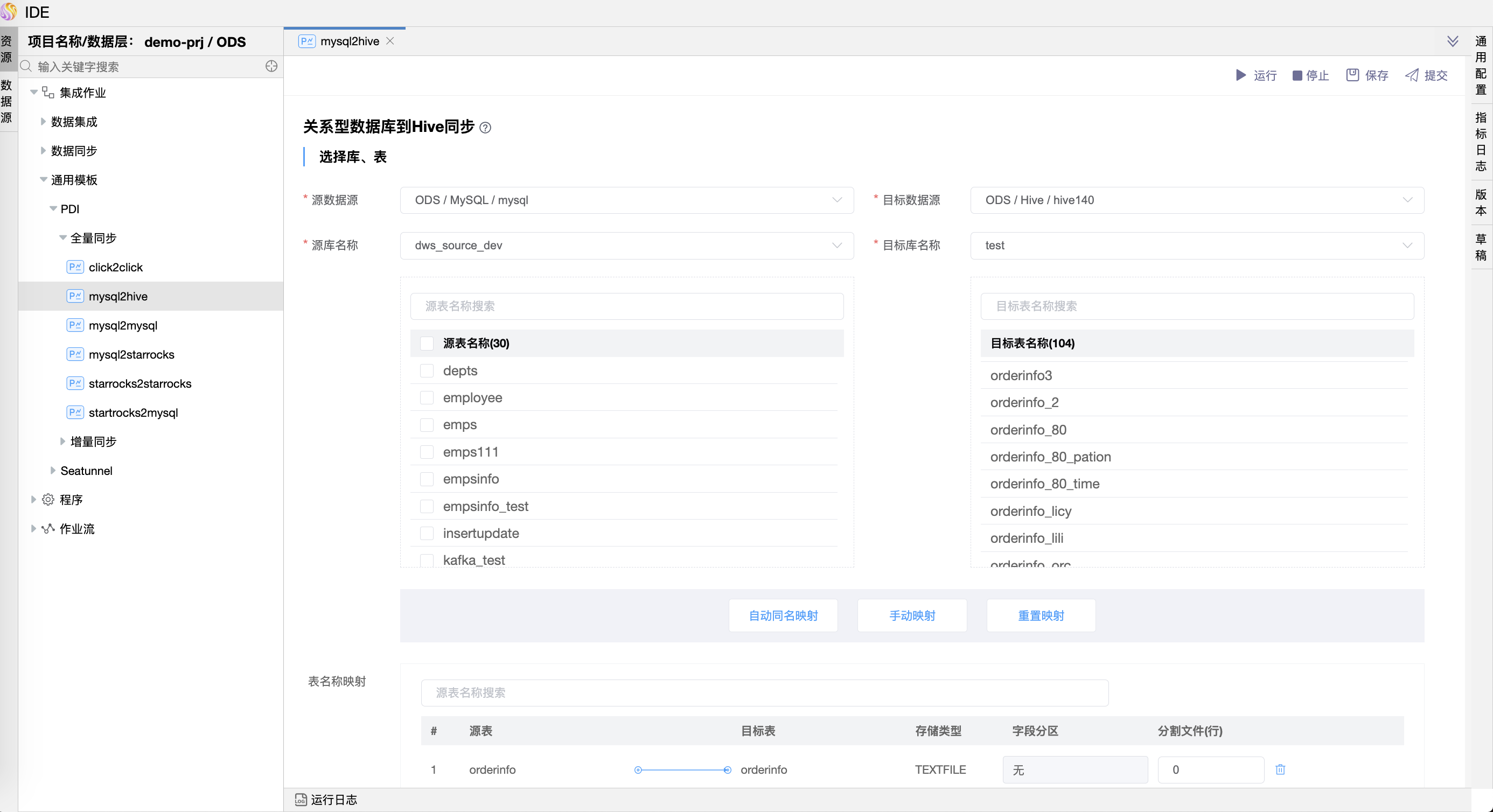
# 关系型数据库到Hive同步(全量)
关系型数据库到Hive同步:用于将关系型数据库的数据迁移到Hive。可以将来源库的多个表或者全部表(整库)的数据迁移到Hive的目标库、表。
Hive库目标表不存在时,会自动创建目标表,可在模型上设置目标表存储格式,支持ORC、PARQUET、TEXTFILE格式;
Hive库目标表存在时,会自动获取表存储格式,支持获取ORC、PARQUET、TEXTFILE格式,其中TEXTFILE格式分隔符支持默认、TAB、逗号。
⚠️ 提示:目标表存在时,要确保源表与目标表的数据结构、字段顺序一致,字段类型相匹配。
# 关系型数据库到StarRocks同步(全量)
关系型数据库到 StarRocks 同步:用于将关系型数据库的数据迁移到 StarRocks。可以将来源库的多个表或者全部表(整库)的数据迁移到 StarRocks 的目标库、表。
该模版的使用向导可以参考"关系型数据库到Hive同步",源数据源是关系型数据库,目标数据源是 StarRocks。
# StarRocks到StarRocks同步(全量)
StarRocks到StarRocks同步:用于将 StarRocks 的数据迁移到 StarRocks。可以将来源库的多个表或者全部表(整库)的数据迁移到 StarRocks 的目标库、表。
该模版的使用向导可以参考"关系型数据库同步",源数据源和目标数据源都是 StarRocks。
# StarRocks到关系型数据库同步(全量)
StarRocks到关系型数据库同步:用于将 StarRocks 的数据迁移到关系型数据库。可以将来源库StarRocks的多个表或者全部表(整库)的数据迁移到关系型数据库的目标库、表。
该模版的使用向导可以参考"StarRocks到StarRocks同步",源数据源是 StarRocks,目标数据源是关系型数据库。
# StarRocks到Hive同步(全量)
StarRocks到Hive同步:用于将StarRocks的数据迁移到Hive。可以将来源库StarRocks的多个表或者全部表(整库)的数据迁移到Hive的目标库、表。
Hive库目标表不存在时,会自动创建目标表,可在模型上设置目标表存储格式,支持ORC、PARQUET、TEXTFILE格式;
Hive库目标表存在时,会自动获取表存储格式,支持获取ORC、PARQUET、TEXTFILE格式,其中TEXTFILE格式分隔符支持默认、TAB、逗号。
该模版的使用向导可以参考"关系型数据库到Hive同步",源数据源是 StarRocks,目标数据源是 Hive。
⚠️ 提示:目标表存在时,要确保源表与目标表的数据结构、字段顺序一致,字段类型相匹配。
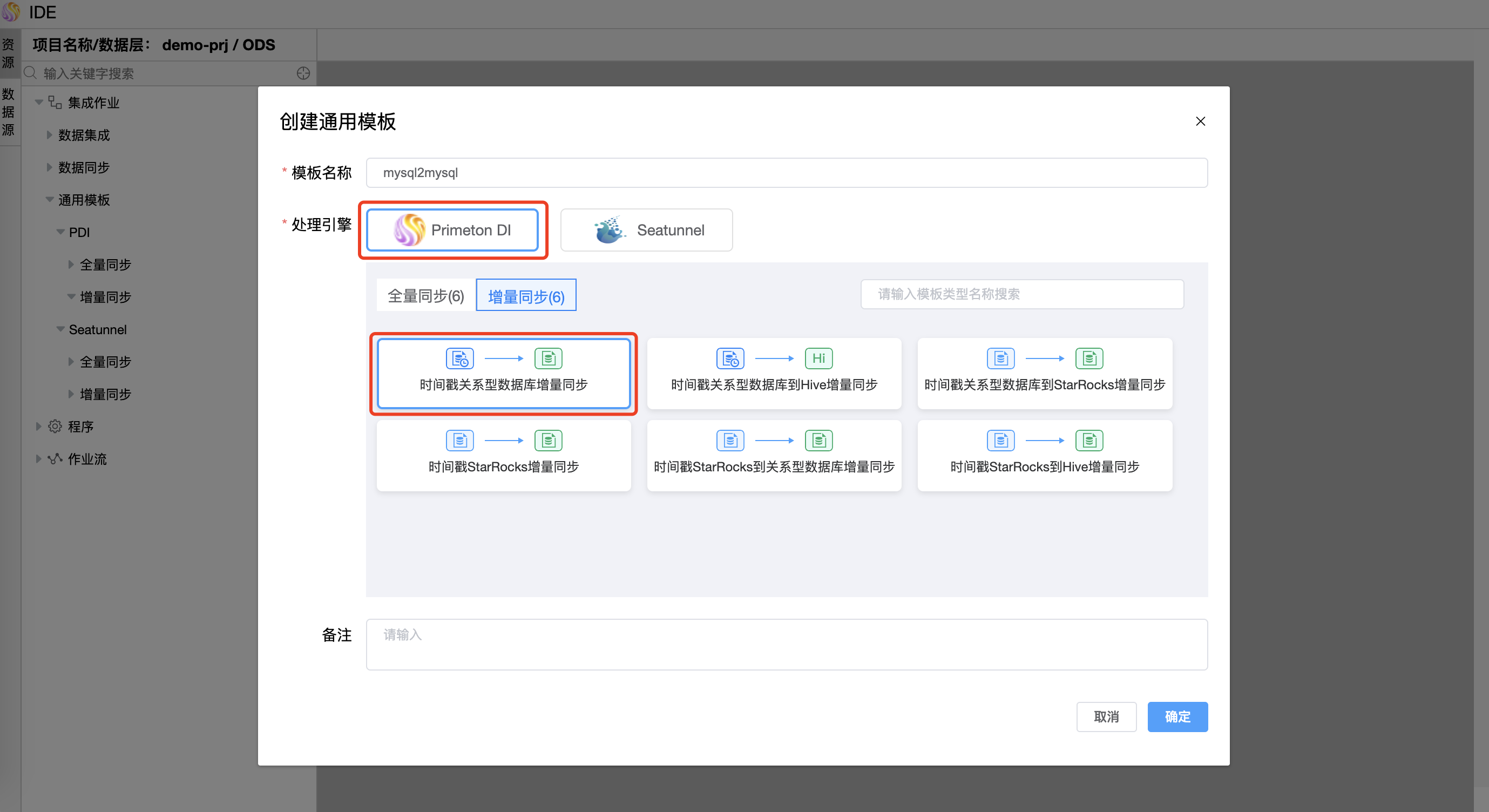
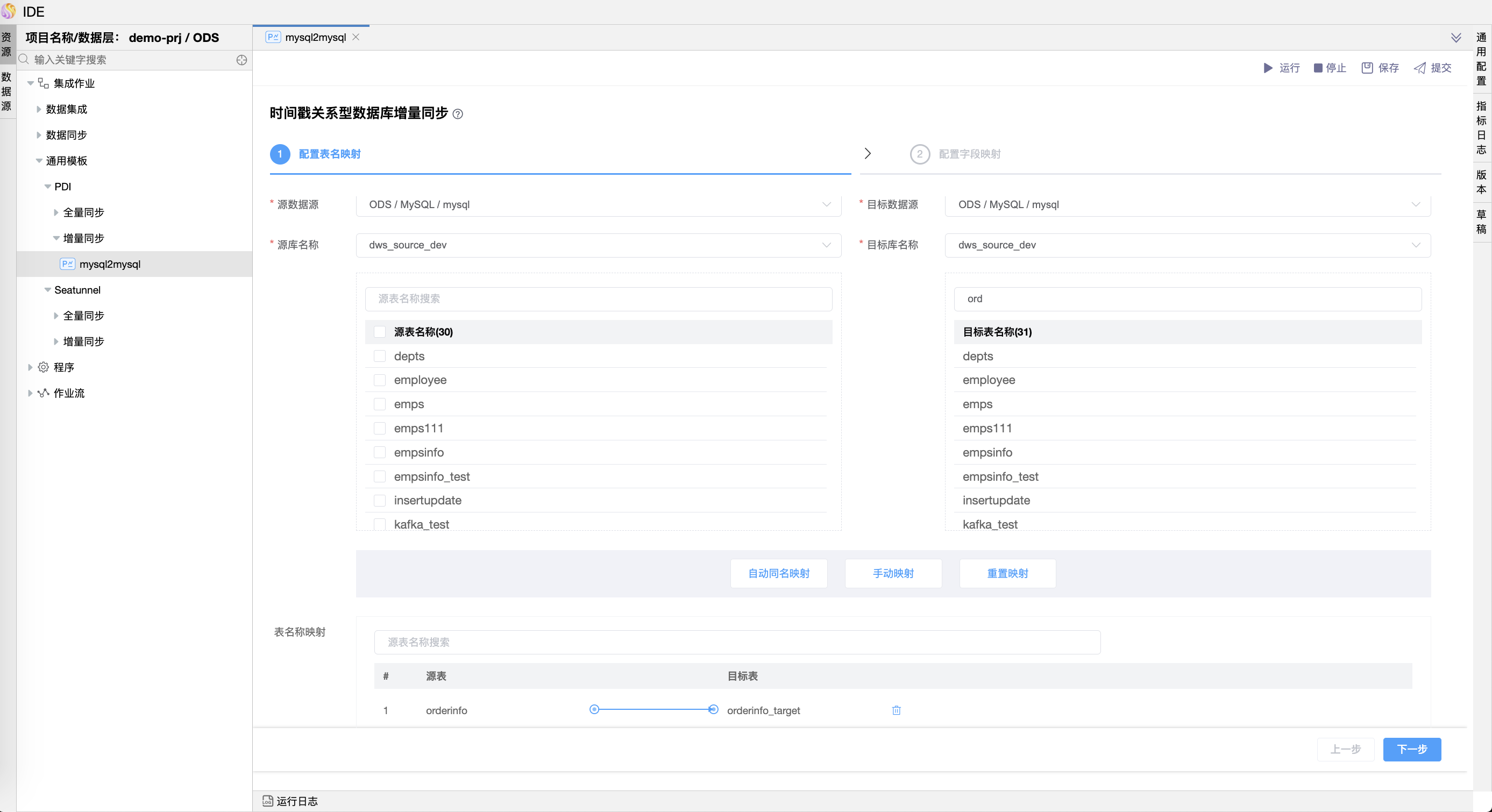
# 时间戳关系型数据库增量同步(增量)
基于时间戳模型,实现从源表向目标表增量同步数据,要求:
- 业务系统表中要必须有一个时间戳字段;
- 业务系统表中需要有可唯一标识某一行的字段作为查询字段。
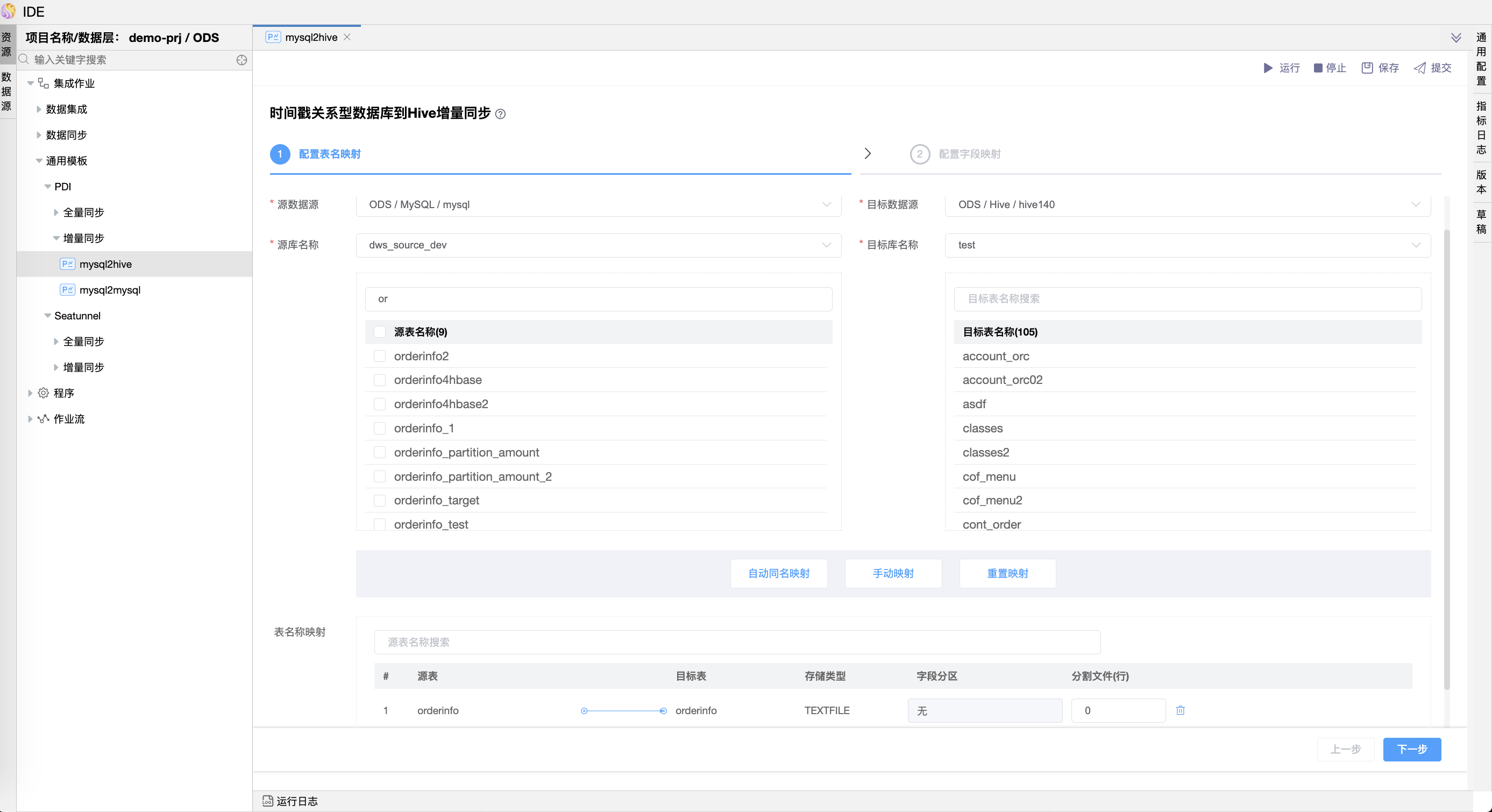
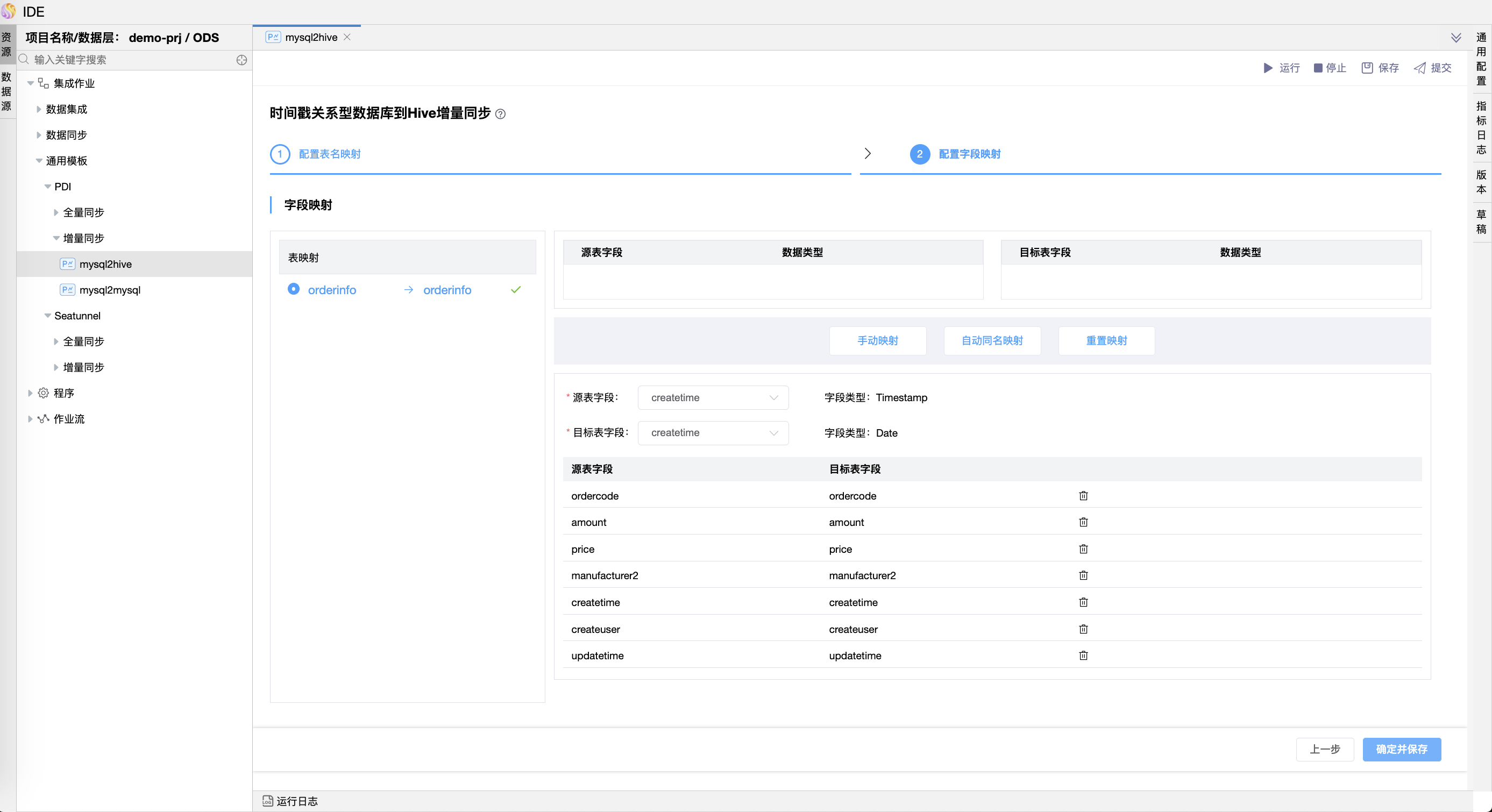
# 时间戳关系型数据库到Hive增量同步(增量)
时间戳关系型数据库到Hive增量同步和时间戳关系型数据库增量同步的向导页面类似,不同的是目标表是hive类型的表,可设置部分字段映射同步。
Hive库目标表不存在时,会自动创建目标表,可在模型上设置目标表存储格式,支持ORC、PARQUET、TEXTFILE格式;
Hive库目标表存在时,会自动获取表存储格式,支持获取ORC、PARQUET、TEXTFILE格式,其中TEXTFILE格式分隔符支持默认、TAB、逗号。
# 时间戳关系型数据库到StarRocks增量同步(增量)
时间戳关系型数据库到StarRocks增量同步和时间戳关系型数据库到Hive增量同步的向导页面类似,不同的是目标表是 StarRocks 类型的表。
# 时间戳StarRocks到StarRocks增量同步(增量)
时间戳StarRocks到StarRocks增量同步和时间戳关系型数据库增量同步的向导页面类似,区别是源表和目标表都是 StarRocks 类型的表。
# 时间戳StarRocks到关系型数据库增量同步(增量)
时间戳StarRocks到关系型数据库增量同步和时间戳关系型数据库增量同步的向导页面类似,源表是 StarRocks 类型的表,目标表是关系型数据库表。
# 时间戳StarRocks到Hive增量同步(增量)
时间戳StarRocks到Hive增量同步和时间戳关系型数据库到Hive增量同步的向导页面类似,源表是 StarRocks 类型的表,目标表是 Hive 库表。